HOW CONTAINERS SUPPORT SERVICE REGISTRATION + DISCOVERY / KUBERNETES BY GOOGLE
SIX MSA PATTERNS.
The most common microservice patterns are Message-Oriented, Event-Driven, Isolated State, Replicating State, Fine-Grained (SOA), and Layered APIs.
Web Services and Business Processes were once complicated by the issue of State. By their nature, Business Processes are Stateful, in that changes occur after each step is performed. The moment of each event is measured as the clock ticks. In the early days, Web Services were always Stateless. This was slowly resolved with non-proprietary solutions such as business process Management Notation (BPMN) and Business Process Execution Language (PBEL). Yet, some Web Services execute or expose computing functions and others are executing business processes. In some cases, a clock matters and other cases, it does not.
Kristopher Sandoval sees a reason for people to be confused, noting “stateless services have managed to mirror a lot of the behavior of stateful services without technically crossing the line.” His explains, “When the state is stored by the server, it generates a session. This is stateful computing. When the state is stored by the client, it generates some kind of data that is to be used for various systems — while technically ‘stateful’ in that it references a state, the state is stored by the client so we refer to it as stateless. Sandoval writes for Nordic APIs.
STATEFUL PATTERNS AND EVI.
Traditional system design favors consistent data queries and mutating state, which is not how distributed architectures are designed. To avoid unexpected results or data corruption, a state needs to be explicitly declared or each component needs to be autonomous. Event-driven patterns provide standards to avoid side-effects of explicitly declaring a state. Message-oriented systems use a queue, while event-based also sets and enforces standards to assure that the design and behavior of messages over the queue have a timestamp. A materialized view of the state can be reconstructed by the service receiving it. It can then replay the events in order. This makes the event-based pattern ideal for EVI.
Any pattern that records time stamps is suitable. Therefore, an index of microservices should also attempt to classify whether a Service has a time-stamp, using the input of whether it is stateful as a key predictor. To start, “service discovery” is required. Enterprise Value Integration (EVI) is then able to leverage the inventory of services to track inputs, transformations, and outputs associated with each customer and each process they consume. This is vital to improve profitability, while also delivering more consistently on brand promises.
EVI is the only brand consulting firm in the world to recognize the importance of containers and serverless computing – and consistently re-engineer organizations to deliver more value.
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications offered by Google. It groups containers that make up an application into logical units for easy management and discovery.
KUBERNETES
Docker has a free open source and paid enterprise versions and is considered a simpler and more flexible container storage platform than Kubernetes. Although it is also open source, it comes from Google and is considered more intricate. Some say overly-complicated. The simplicity of Docker is illustrated through service discovery. As long as the container name is used as hostname, a container can always discover other containers on the same stack. Docker Cloud uses directional links recorded in environment variables to provides a basic service discovery functionality. The complexity of Kubernetes is illustrated through service registration and discovery. Kubernetes is predicated in the idea that a Service is a REST object. This means that a Service definition can be POSTed to the apiserver to create a new instance. Kubernetes offers Endpoints API, which is updated when a Service changes. Google explains, “for non-native applications, Kubernetes offers a virtual-IP-based bridge to Services which redirects to the backend Pods.” A group of containers that deployed together on the same host is a Kubernetes pod. Kubernetes supports domain name servers (DNS) discovery as well as environmental variables. Google strongly recommends the DNS approach.
KUBERNETES: TOP TEN LINKS
1. What is Kubernetes?
2. Kubernetes on RedHat
3. Azure Kubernetes Service (AKS)
4. IBM Cloud Kubernetes Service
5. Introduction to Kubernetes by Digital Ocean
6. Kubernetes Components
7. Understanding Kubernetes Objects
8. Kubernetes on OpenStack
9. Lessoned Learned from Using Kubernetes for One Year
10. Download Kubernetes on GitHub
CONTAINERS & CLOUD COMPUTING: TOP TEN LINKS
1. What are Containers?
2. Containers and Cloud Computing
3. Containers vs. Virtual Machines
4. What is a Linux Container?
5. Comparing Kubernetes and Docker
6. Amazon Elastic Container Service (Amazon ECS)
7. Run containers without servers with AWS Fargate
8. RedHat OpenShift Container Platform
9. Rancher Container Management Platform
10. IronWorker and Serverless Computing
CONTAINERS (by Google)
At Ninja Van, running applications in a stable, scalable environment is business-critical. We are a fast-growing tech-enabled express logistics business with operations across South East Asia. In the past 12 months, we’ve partnered with close to two million businesses to deliver around two million parcels daily to customers, with the help of more than 40,000 workers and employees.
We are an established customer of Google Cloud, and continue to work closely with them to expand into new products and markets, including supply chain management and last mile courier services.
Deploying a secure, stable, container platformTo run the applications and microservices architecture that enable our core businesses, we opted to deploy a secure and stable container platform. We had been early adopters of containerization. We were initially running our container workload in CoreOS with a custom scheduler, Fleet. As we monitor the activities in the open source community, it was evident Kubernetes was gaining more traction and is becoming more and more popular. We decided to run our own Kubernetes cluster and API server, later deploying a number of Compute Engine virtual machines, consisting of both control plane and worker nodes.
As we dived deeper into Kubernetes, we realized that a lot of what we did was already baked into its core functionalities, such as service discovery. This feature enables applications and microservices to communicate with each other without the need to know where the container is deployed to among the worker nodes. We felt that if we continued maintaining our discovery system, we would just be reinventing the wheel. Thus, we dropped what we had in favor of this Kubernetes core feature.
We also found the opportunity to engage with and contribute to the open source community working on Kubernetes compelling. With Kubernetes being open standards-based, we gained the freedom and flexibility to adapt our technology stack to our needs.
However, we found upgrading a self-managed Kubernetes challenging and troublesome in the early days and decided to move to a fully managed Kubernetes service. Among other benefits, we could upgrade Kubernetes easily through Google Kubernetes Engine (GKE) user interface or Google Cloud command line tool. We could also enable auto upgrades simply by specifying an appropriate release channel.
Simplifying the operation of multiple GKE clustersWith a technology stack based on open-source technologies, we have simplified the operation of multiple clusters in GKE. For monitoring and logging operations, we have moved to a centralized architecture to colocate the technology stack on a single management GKE cluster. We use Elasticsearch, Fluentbit and Kibana for logging and Thanos, Prometheus and Grafana for monitoring. When we first started, logging and monitoring were distributed across individual clusters, which meant that administrators had to access the clusters separately which led to a lot of operational inefficiencies. This also meant maintaining duplicated charts across different instances of Kibana and Grafana.
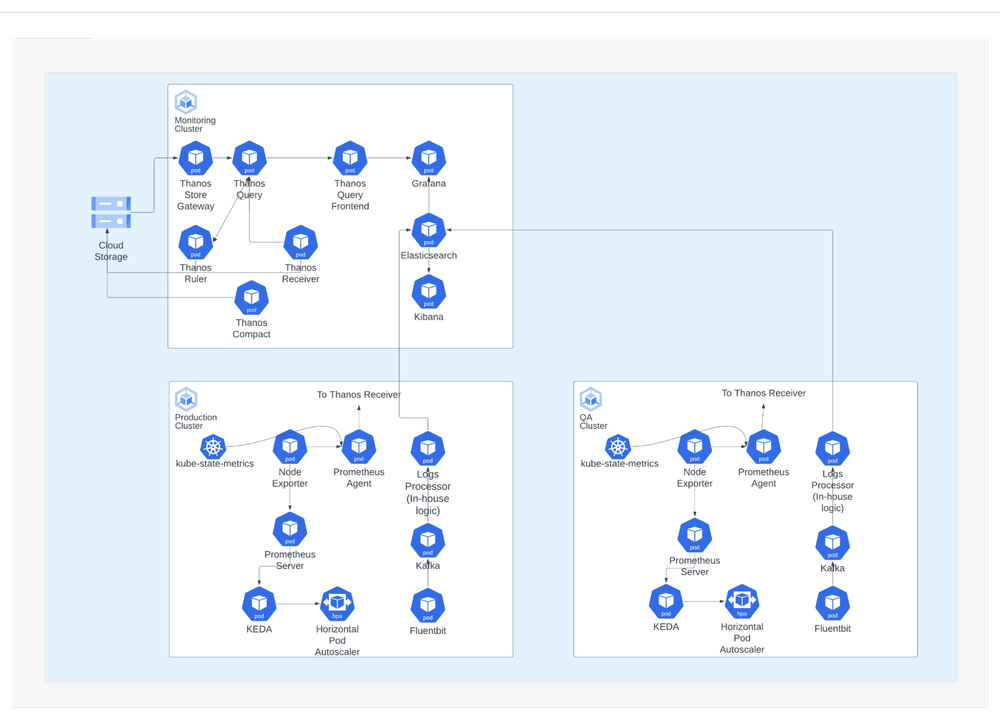
For CI/CD, we run a dedicated DevOps GKE cluster used for hosting developer toolsets and running the pipelines. We embrace the Atlassian suite of services, such as JIRA, Confluence, Bitbucket, Bamboo to name a few. These applications are hosted in the same DevOps GKE cluster.
Our CI/CD is centralized, but custom steps can be put in, giving some autonomy to teams. When a team pushes out new versions of codes, our CI pipeline undertakes the test and build processes. This then produces container image artifacts for backend services and minified artifacts for frontend websites. Typically, the pipelines are parameterized to push out and test the codes in development and testing environments, and subsequently deploy them into sandbox and production. Depending on their requirements, application teams have the flexibility to opt for a fully automated pipeline or a semi-automated one, that requires manual approval for deployment to production.
Autoscaling also comes into play during runtime. As more requests come in, we need to scale up to more containers, but shrink down automatically as the number of requests decreases. To support autoscaling based on our metrics, we integrate KEDA to our technology stack.
Delivering a seamless development experienceIn a sense, our developers are our customers as well as our colleagues. We aim to provide a frictionless experience for them by automating the testing, deployment, management and operation of application services and infrastructure. By doing this, we allow them to focus on building the application they’re assigned.
To do this, we’re using DevOps pipelines to automate and simplify infrastructure provisioning and software testing and release cycles. Teams can also self-serve and spin up GKE clusters with the latest environment builds mirroring production with non-production sample data preloaded, which gives them a realistic environment to test the latest fixes and releases.
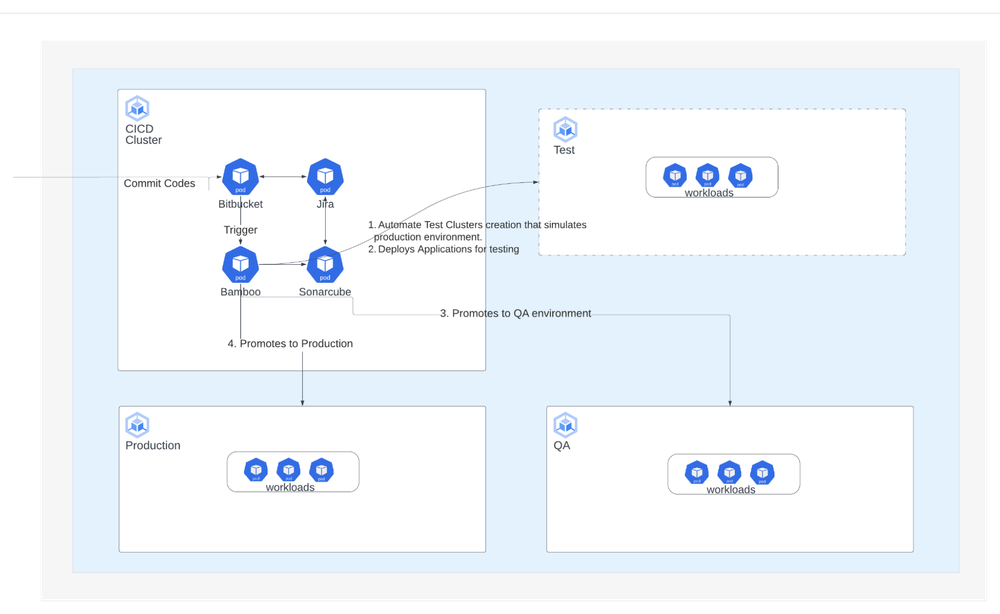
As a build proceeds to deployment, they can visit a Bamboo CI/CD Console to track progress.
Code quality is critical to our development process. An engineering excellence sub-vertical within our business monitors code quality through part of our CI/CD using the SonarQube open-source code inspection tool. We set stringent unit test coverage percentage requirements and do not allow anything into our environment that fails unit or integration testing.
We release almost once a day excluding code freezes on days like Black Friday or Cyber Monday, when we only release bug fixes or features that need to be deployed urgently during demand peaks. While we’ve not changed our release schedule with GKE, we’ve been able to undertake concurrent builds in parallel environments, enabling us to effectively manage releases across our 200-microservice architecture.
Latency key to Google Cloud and GKE selectionWhen we moved from other cloud providers to Google Cloud and GKE, the extremely low latency between Google Cloud data centers, in combination with reliability, scalability and competitive pricing, gave us confidence Google Cloud was the right choice. In a scenario with a lot of people using the website, we can provide a fast response time and a better customer experience.
In addition, Google Cloud makes the patching and upgrading of multiple GKE clusters a breeze by automating the upgrade process and proactively informing us when an automated upgrade or change threatens to break one of our APIs.
Google Cloud and GKE also open up a range of technical opportunities for our business, including simplification. Many of our services use persistent storage, and GKE provides a simple way to automatically deploy and manage them through their Container Storage Interface (CSI) driver. The CSI driver enables native volume snapshots and in conjunction with Kubernetes CronJob, where we can easily take automated backups of the disks running services such as TiDB, MySQL, Elasticsearch and Kafka. On the development front, we are also exploring Skaffold, which opens up possibilities for development teams to improve their inner development loop cycle and develop more effectively as if their local running instance is deployed within a Kubernetes cluster.
Overall, the ease of management of GKE means we can manage our 200-microservice architecture in 15 clusters with just 10 engineers even as the business continues to grow.
If you want to try this out yourself, check out a hands-on tutorial where you will set up a continuous delivery pipeline in GKE that automatically rebuilds, retests, and redeploys changes to a sample application.
Patent-search platform provider IPRally is growing quickly, servicing global enterprises, IP law firms, and multiple national patent and trademark offices. As the company grows, so do its technology needs. It continues to train its models for greater accuracy, adding 200,000 searchable records for customer access weekly, and mapping new patents.
With millions of patent documents published annually – and the technical complexity of those documents increasing — it can take even the most seasoned patent professional several hours of research to resolve a case with traditional patent search tools. In 2018, Finnish firm IPRally set out to tackle this problem with a graph-based approach.
“Search engines for patents were mostly complicated boolean ones, where you needed to spend hours building a complicated query,” says Juho Kallio, CTO and co-founder of the 50-person firm. “I wanted to build something important and challenging.”
Using machine learning (ML) and natural language processing (NLP), the company has transformed the text from over 120 million global patent documents into document-level knowledge graphs embedded into a searchable vector space. Now, patent researchers can receive relevant results in seconds with AI-selected highlights of key information and explainable results.
To meet those needs, IPRally built a customized ML platform using Google Kubernetes Engine (GKE) and Ray, an open-source ML framework, balancing efficiency, performance and streamlining machine learning operations (MLOps). The company uses open-source KubeRay to deploy and manage Ray on GKE, which enables them to leverage cost-efficient NVIDIA GPU Spot instances for exploratory ML research and development. It also uses Google Cloud data building blocks, including Cloud Storage and Compute Engine persistent disks. Next on the horizon is expanding to big data solutions with Ray Data and BigQuery.
“Ray on GKE has the ability to support us in the future with any scale and any kind of distributed complex deep learning,” says Kallio.
A custom ML platform built for performance and efficiencyThe IPRally engineering team’s primary focus is on R&D and how it can continue to improve its Graph AI to make technical knowledge more accessible. With just two DevOps engineers and one MLOps engineer, IPRally was able to build its own customized ML platform with GKE and Ray as key components.
A big proponent of open source, IPRally transitioned everything to Kubernetes when their compute needs grew. However, they didn’t want to have to manage Kubernetes themselves. That led them to GKE, with its scalability, flexibility, open ecosystem, and its support for a diverse set of accelerators. All told, this provides IPRally the right balance of performance and cost, as well as easy management of compute resources and the ability to efficiently scale down capacity when they don’t need it.
“GKE provides the scalability and performance we need for these complex training and serving needs and we get the right granularity of control over data and compute,” says Kallio.
One particular GKE capability that Kallio highlights is container image streaming, which has significantly accelerated their start-up time.
“We have seen that container image streaming in GKE has a significant impact on expediting our application startup time. Image streaming helps us accelerate our start-up time for a training job after submission by 20%,” he shares. “And, when we are able to reuse an existing pod, we can start up in a few seconds instead of minutes.”
The next layer is Ray, which the company uses to scale the distributed, parallelized Python and Clojure applications it uses for machine learning. To more easily manage Ray, IPRally uses KubeRay, a specialized tool that simplifies Ray cluster management on Kubernetes. IPRally uses Ray for the most advanced tasks like massive preprocessing of data and exploratory deep learning in R&D.
“Interoperability between Ray and GKE autoscaling is smooth and robust. We can combine computational resources without any constraints,” says Kallio.
The heaviest ML loads are mainly deployed on G2 VMs featuring eight NVIDIA L4 GPUs featuring up to eight NVIDIA L4 Tensor Core GPUs, which deliver cutting-edge performance-per-dollar for AI inference workloads. And by leveraging them within GKE, IPRally facilitates the creation of nodes on-demand, scales GPU resources as needed, thus optimizing its operational costs. There is a single Terraform-provisioned Kubernetes cluster in each of the regions that IPRally searches for the inexpensive spot instances. GKE and Ray then step in for compute orchestration and automated scaling.
To further ease MLOps, IPRally built its own thin orchestration layer, IPRay, atop KubeRay and Ray. This layer provides a command line tool for data scientists to easily provision a templated Ray cluster that scales efficiently up and down and that can run jobs in Ray without needing to know Terraform. This self-service layer reduces friction and allows both engineers and data scientists to focus on their higher-value work.
Technology paves the way for strong growthThrough this selection of Google Cloud and open-source frameworks, IPRally has shown that a startup can build an enterprise-grade ML platform without spending millions of dollars. Focusing on providing a powerful MLOps and automation foundation from its earliest days has paid dividends in efficiency and the team’s ability to focus on R&D.
“Crafting a flexible ML infrastructure from the best parts has been more than worth it,” shares Jari Rosti, an ML engineer at IPRally. “Now, we’re seeing the benefits of that investment multiply as we adapt the infrastructure to the constantly evolving ideas of modern ML. That’s something other young companies can achieve as well by leveraging Google Cloud and Ray.”
Further, the company has been saving 70% of ML R&D costs by using Spot instances. These affordable instances offer the same quality VMs as on-demand instances but are subject to interruption. But because IPRally’s R&D workloads are fault-tolerant, they are a good fit for Spot instances.
IPRally closed a €10m A round investment last year, and it’s forging on with ingesting and processing IP documentation from around the globe, with a focus on improving its graph neural network models and building the best AI platform for patent searching. With 3.4 million patents filed in 2022, the third consecutive year of growth, data will keep flowing and IPRally can continue helping intellectual property professionals find every relevant bit of information.
"With Ray on GKE, we've built an ML foundation that is a testament to how powerful Google Cloud is with AI," says Kallio. “And now, we’re prepared to explore far more advanced deep learning and to keep growing.”
Google Kubernetes Engine (GKE) has emerged as a leading container orchestration platform for deploying and managing containerized applications. But GKE is not just limited to running stateless microservices — its flexible design supports workloads that need to persist data as well, via tight integrations with persistent disk or blob storage products including Persistent Disk, Cloud Storage, and Filestore.
And for organizations that need even stronger throughput and performance, there’s Hyperdisk, Google Cloud's next-generation block storage service that allows you to modify your capacity, throughput, and IOPS-related performance and tailor it to your workloads, without having to re-deploy your entire stack.
Today, we’re excited to introduce support for Hyperdisk Balanced storage volumes on GKE, which joins the Hyperdisk Extreme and Hyperdisk Throughput options, and is a good fit for workloads that typically rely on persistent SSDs — for example, line-of-business applications, web applications, and databases. Hyperdisk Balanced is supported on 3rd+ generation instance types. For instance type compatibility please reference this page.
Understanding HyperdiskFirst, let’s start with what it means to fine-tune your throughput with Hyperdisk? What about tuning IOPS and capacity?
Tuning IOPS means refining the input/output operations per second (IOPS) performance of a storage device. Hyperdisk allows you to provision only the IOPS you need, and does not share it with other volumes on the same node.
Tuning throughput means enhancing the amount of data or information that can be transferred or processed in a specified amount of time. Hyperdisk allows you to specify exactly how much throughput a given storage volume should have without limitations imposed by other volumes on the same node.
Expanding capacity means you can increase the size of your storage volume. Hyperdisk can be provisioned for the exact capacity you need and extended as your storage needs grow.
These Hyperdisk capabilities translate in to the following benefits:
First, you can transform your environment's stateful environment through flexibility, ease of use, scalability and management — with a potential cost savings to boost. Imagine the benefit of a storage area network environment without the management overhead.
Second, you can build lower-cost infrastructure by rightsizing the machine types that back your GKE nodes, optimizing your GKE stack while integrating with GKE CI/CD, security and networking capabilities.
Finally, you get predictability — the consistency that comes with fine-grained tuning for each individual node and its required IOPS. You can also use this to fine-tune for ML model building/training/deploying, as Hyperdisk removes the element of throughput and IOPS from all PDs sharing the same node bandwidth, placing it on the provisioned Hyperdisk beneath it.
Compared with traditional persistent disk, Hyperdisk’s storage performance is decoupled from the node your application is running on. This gives you more flexibility with your IOPs and throughput, while reducing the possibility that overall storage performance would be impacted by a noisy neighbor.
On GKE, the following types of Hyperdisk volumes are available:
Hyperdisk Balanced - General-purpose volume type that is the best fit for most workloads, with up to 2.4GBps of throughput and 160k IOPS. Ideal for line-of-business applications, web applications, databases, or boot disks.
Hyperdisk Throughput - Optimized for cost-efficient high-throughput workloads, with up to 3 GBps throughput (>=128 KB IO size). Hyperdisk Throughput is targeted at scale-out analytics (e.g., Kafka, Hadoop, Redpanda) and other throughput-oriented cost-sensitive workloads, and is supported on GKE Autopilot and GKE Standard clusters.
Hyperdisk Extreme - Specifically optimized for IOPS performance, such as large-scale databases that require high IOPS performance. Supported on Standard clusters only.
Getting started with Hyperdisk on GKETo provision Hyperdisk you first need to make sure your cluster has the necessary StorageClass loaded that references the disk. You can add the necessary IOPS/Throughput to the storage class or go with the defaults, which are 3,600 IOPs and 140MiBps (Docs).
YAML to Apply to GKE cluster
code_block <ListValue: [StructValue([('code', 'apiVersion: storage.k8s.io/v1\r\nkind: StorageClass\r\nmetadata:\r\nname: balanced-storage\r\nprovisioner: pd.csi.storage.gke.io\r\nvolumeBindingMode: WaitForFirstConsumer\r\nallowVolumeExpansion: true\r\nparameters:\r\ntype: hyperdisk-balanced\r\nprovisioned-throughput-on-create: "200Mi" #optional\r\nprovisioned-iops-on-create: "5000" #optional'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e03a7bd9460>)])]>After you’ve configured the StorageClass, you can create a persistent volume claim that references it.
code_block <ListValue: [StructValue([('code', 'kind: PersistentVolumeClaim\r\napiVersion: v1\r\nmetadata:\r\nname: postgres\r\nspec:\r\naccessModes:\r\n- ReadWriteOnce\r\nstorageClassName: balanced-storage\r\nresources:\r\nrequests:\r\nstorage: 1000Gi'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x3e03a7bd9d60>)])]> Take control of your GKE storage with HyperdiskTo recap, Hyperdisk lets you take control of your cloud infrastructure storage, throughput, IOPS, and capacity, combining the speed of existing PD SSD volumes with the flexibility to fine-tune to your specific needs, by decoupling disks from the node that your workload is running on.
For more, check out the following sessions from Next ‘24:
Next generation storage: Designing storage for the futureA primer on data on Kubernetes
And be sure to check out these resources:
How to create a Hyperdisk on GKE
It’s a great time for organizations innovating with AI. Google recently launched Gemini, our largest and most capable AI model, followed by Gemma, a family of lightweight, state-of-the art open models built from research and technology that we used to create the Gemini models. Gemma models achieve best-in-class performance for their size (Gemma 2B and Gemma 7B) compared to other open models, and are pre-trained and equipped with instruction-tuned variants to enable research and development. The release of Gemma and our updated platform capabilities are the next phase of our commitment to making AI more open and accessible to developers on Google Cloud. Today, let’s take a look at the enhancements we’ve made to Google Kubernetes Engine (GKE) to help you serve and deploy Gemma on GKE Standard as well as Autopilot:
Integration with Hugging Face, Kaggle and Vertex AI Model Garden: If you are a GKE customer, you can deploy Gemma by starting in Hugging Face, Kaggle or Vertex AI Model Garden. This lets you easily deploy models from your preferred repositories to the infrastructure of your choice.
GKE notebook experience using Colab Enterprise: Developers who prefer an IDE-like notebook environment for their ML project can now deploy and serve Gemma using Google Colab Enterprise.
A cost-efficient, reliable and low-latency AI inference stack: Earlier this week we announced JetStream, a highly efficient AI-optimized large language model (LLM) inference stack to serve Gemma on GKE. Along with JetStream, we introduced a number of cost- and performance-efficient AI-optimized inference stacks for serving Gemma across ML Frameworks (PyTorch, JAX) powered by Cloud GPUs or Google’s purpose-built Tensor Processor Units (TPU). Earlier today we published a performance deepdive of Gemma on Google Cloud AI optimized infrastructure for training and serving generative AI workloads.
Now, whether you are a developer building generative AI applications, an ML engineer optimizing generative AI container workloads, or an infrastructure engineer operationalizing these container workloads, you can use Gemma to build portable, customizable AI applications and deploy them on GKE.
Let’s walk through each of these releases in more detail.
Hugging Face, Vertex AI Model Garden and Kaggle integrationRegardless of where you get your AI models, our goal is to make it easy for you to deploy them on GKE.
Hugging FaceEarlier this year, we signed a strategic partnership with Hugging Face, one of the preferred destinations for the AI community, to provide data scientists, ML engineers and developers with access to the latest models. Hugging Face launched the Gemma model card, allowing you to deploy Gemma from Hugging Face directly to Google Cloud. Once you click the Google Cloud option, you will be redirected to Vertex Model Garden, where you can choose to deploy and serve Gemma on Vertex AI or GKE.
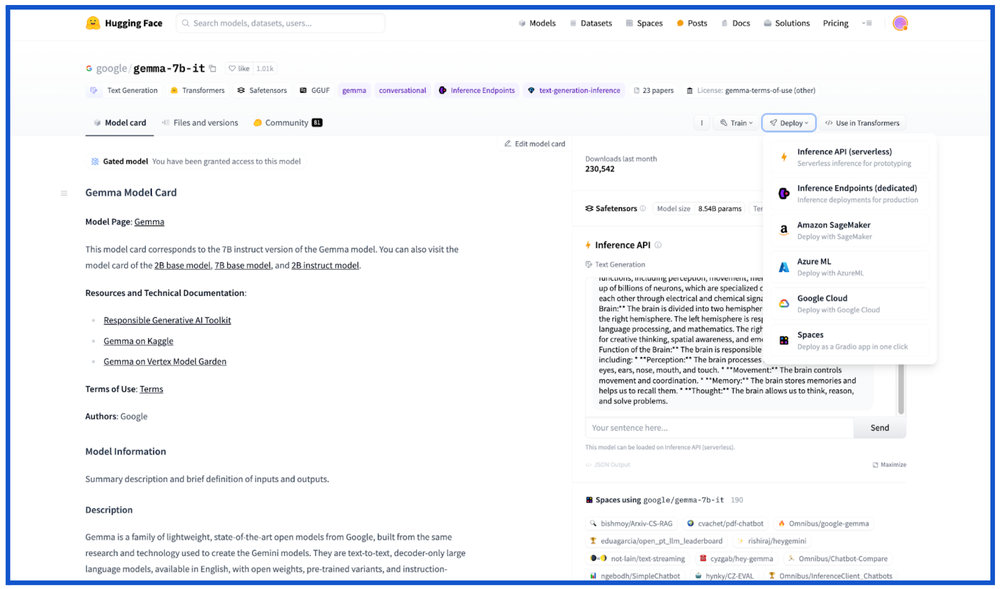 Vertex Model Garden
Vertex Model Garden
Gemma joins 130+ models in Vertex AI Model Garden, including enterprise-ready foundation model APIs, open-source models, and task-specific models from Google and third parties.
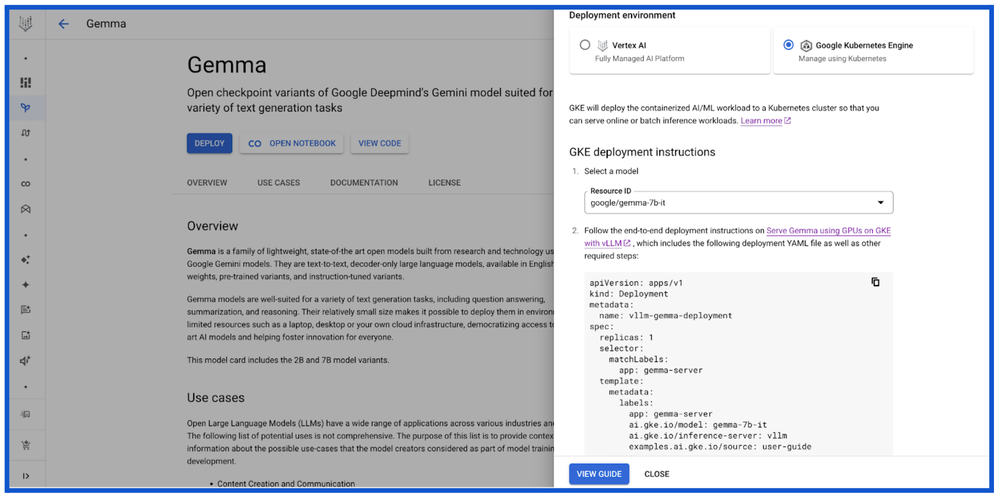 Kaggle
Kaggle
Kaggle allows developers to search and discover thousands of trained, ready-to-deploy machine learning models in one place. The Gemma model card on Kaggle provides a number of model variations (PyTorch, FLAX, Transformers, etc) to enable an end-to-end workflow for downloading, deploying and serving Gemma on a GKE cluster. Kaggle customers can also “Open in Vertex,” which takes them to Vertex Model Garden where they can see the option to deploy Gemma either on Vertex AI or GKE as described above. You can explore real-world examples using Gemma shared by the community on Gemma's model page on Kaggle.
Google Colab Enterprise notebooksDevelopers, ML engineers and ML practitioners can also deploy and serve Gemma on GKE using Google Colab Enterprise notebooks via Vertex AI Model Garden. Colab Enterprise notebooks come with pre-populated instructions in the code cells, providing the flexibility to deploy and run inference on GKE using an interface that is preferred by developers, ML engineers and scientists.
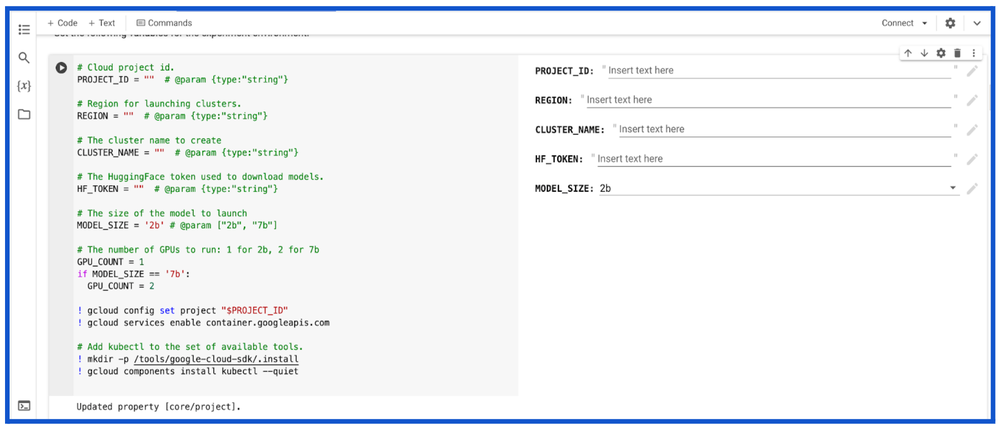 Serve Gemma models on AI-optimized infrastructure
Serve Gemma models on AI-optimized infrastructure
When running inference at scale, performance per dollar and cost of serving are critical. Powered by an AI-optimized infrastructure stack equipped with Google Cloud TPUs and GPUs, GKE enables high-performance and cost-efficient inference for a broad range of AI workloads.
“GKE empowers our ML pipelines by seamlessly integrating TPUs and GPUs, allowing us to leverage the strengths of each for specific tasks and reduce latency and inference costs. For instance, we efficiently process text prompts in batches using a large text encoder on TPU, followed by employing GPUs to run our in-house diffusion model, which utilizes the text embeddings to generate stunning images.” - Yoav HaCohen, Ph.D, Core Generative AI Research Team Lead, Lightricks
We are excited to extend these benefits to workloads that are equipped with Gemma on GKE.
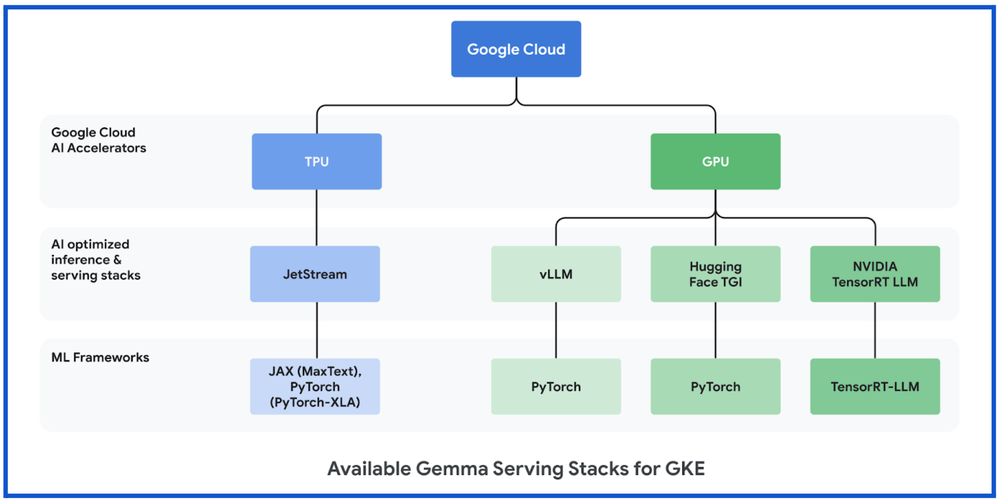 Gemma on GKE with TPUs
Gemma on GKE with TPUs
If you prefer to use Google Cloud TPU accelerators with your GKE infrastructure, several AI-optimized inference and serving frameworks also now support Gemma on Google Cloud TPUs, and already support the most popular LLMs. These include:
JetStreamFor optimizing inference performance for PyTorch or JAX LLMs on Google Cloud TPUs, we launched JetStream(MaxText) and JetStream(PyTorch-XLA), a new inference engine specifically designed for LLM inference. JetStream represents a significant leap forward in both performance and cost efficiency, offering strong throughput and latency for LLM inference on Google Cloud TPUs. JetStream is optimized for both throughput and memory utilization, providing efficiency by incorporating advanced optimization techniques such as continuous batching, int8 quantization for weights, activations and KV cache. JetStream is the recommended TPU inference stack from Google.
Get started with JetStream inference for Gemma on GKE and Google Cloud TPUs with this tutorial.
Gemma on GKE with GPUsIf you prefer to use Google Cloud GPU accelerators with your GKE infrastructure, several AI-optimized inference and serving frameworks also now support Gemma on Google Cloud GPUs, and already support the most popular LLMs. These include:
vLLMUsed to increase serving throughput for PyTorch generative AI users, vLLM is a highly optimized open-source LLM serving framework. vLLM includes features such as:
An optimized transformer implementation with PagedAttention
Continuous batching to improve the overall serving throughput
Tensor parallelism and distributed serving on multiple GPUs
Get started with vLLM for Gemma on GKE and Google Cloud GPUs with this tutorial.
Text Generation Inference (TGI)Designed to enable high-performance text generation, Text Generation Inference (TGI) is a highly optimized open-source LLM serving framework from Hugging Face for deploying and serving LLMs. TGI includes features such as continuous batching to improve overall serving throughput, and tensor parallelism and distributed serving on multiple GPUs.
Get started with Hugging Face Text Generation Inference for Gemma on GKE and Google Cloud GPUs with this tutorial.
TensorRT-LLMTo optimize inference performance of the latest LLMs on Google Cloud GPU VMs powered by NVIDIA Tensor Core GPUs, customers can use NVIDIA TensorRT-LLM, a comprehensive library for compiling and optimizing LLMs for inference. TensorRT-LLM supports features like paged attention, continuous in-flight batching, and others.
Get started with NVIDIA Triton and TensorRT LLM backend on GKE and Google Cloud GPU VMs powered by NVIDIA Tensor Core GPUs with this tutorial.
Train and serve AI workloads your wayWhether you’re a developer building new gen AI models with Gemma, or choosing infrastructure on which to train and serve those models, Google Cloud provides a variety of options to meet your needs and preferences. GKE provides a self-managed, versatile, cost-effective, and performant platform on which to base the next generation of AI model development.
With integrations into all the major AI model repositories (Vertex AI Model Garden, Hugging Face, Kaggle and Colab notebooks), and support for both Google Cloud GPU and Cloud TPU, GKE offers several flexible ways to deploy and serve Gemma. We look forward to seeing what the world builds with Gemma and GKE. To get started, please refer to the user guides on the Gemma on GKE landing page.
KUBERNETES (by Reddit)
This monthly post can be used to share Kubernetes-related job openings within your company. Please include:
Name of the company Location requirements (or lack thereof) At least one of: a link to a job posting/application page or contact detailsIf you are interested in a job, please contact the poster directly.
Common reasons for comment removal:
Not meeting the above requirements Recruiter post / recruiter listings Negative, inflammatory, or abrasive tone submitted by /u/gctaylor [link] [comments]What are you up to with Kubernetes this week? Evaluating a new tool? In the process of adopting? Working on an open source project or contribution? Tell /r/kubernetes what you're up to this week!
submitted by /u/gctaylor [link] [comments]  submitted by /u/AmiditeX [link] [comments]
submitted by /u/AmiditeX [link] [comments]
Mounting the secrets works fine, the issue arose last week when we deleted a secret from the key vault without updating the Secret Provider Class manifest. Because the secret was missing from the key vault it (naturally) couldn't be mounted for any new pods, which therefore failed immediately. We soon had 50 failing pods until we found out what we had done.
Short question: Is it possible to simply ignore or warn on missing secrets instead of failing the pod start?
The yamls in question:
Secret provider class:
apiVersion: secrets-store.csi.x-k8s.io/v1 kind: SecretProviderClass metadata: name: $(SecretProviderClassName) namespace: $(PowerbotNamespace) spec: provider: azure parameters: usePodIdentity: "false" clientID: $(ClientId) tenantId: $(TenantID) keyvaultName: $(KeyVaultName) # Secrets that should be accessible by pods. objects: | array: - | objectType: secret objectName: secret_1 - | objectType: secret objectName: secret_2And the yaml for the pod:
apiVersion: batch/v1 kind: CronJob metadata: name: $(ImageName) namespace: $(Namespace) labels: app: $(ImageName) env: $(Environment) spec: # Every 5 minutes. schedule: "5 * * * *" jobTemplate: spec: template: spec: serviceAccountName: $(ServiceAccountName) containers: - name: $(ImageName) image: $(ACR)/$(ImagePrefix)$(ImageName):$(ImageTag) args: ["python", "-m", "src.my_script"] resources: requests: memory: "512Mi" cpu: "0.5" limits: memory: "4Gi" cpu: "1" volumeMounts: - name: secrets-store-inline mountPath: $(SecretMountPath) readOnly: true volumes: - name: secrets-store-inline csi: driver: secrets-store.csi.k8s.io readOnly: true volumeAttributes: secretProviderClass: $(SecretProviderClassName) submitted by /u/killercap88 [link] [comments]  submitted by /u/meysam81 [link] [comments]
submitted by /u/meysam81 [link] [comments]
Seriously, I was talking to someone about Kubernetes and if they are facing any challenges. He told me about upgrading kubernetes and they are not using EKS? What exactly is it? Is it a big problem?
submitted by /u/OkUnderstanding269 [link] [comments]While setting up a new eks cluster.
I often come across the below error:
[ec2-user@ip-17-5-10-42 ~]$ kubectl get svc
E0429 10:58:06.018674 3701 memcache.go:265] couldn't get current server API group list: Get "<API-server-endpoint>/api?timeout=32s": dial tcp 17.5.29.102:443: i/o timeout
what is E0429?
Also, what am I getting wrong here for my kubectl commands not to work ?
submitted by /u/srimanthudu6416 [link] [comments]I have created a config map from my appsettings.json In Startup.cs, in my C# .NET code, how do I differentiate between whether my application should use appsettings.json during local and that it should take the configuration in configmap for the KOB deployed service. What code changes do I make so that it takes the values for both running cases?
submitted by /u/akowta [link] [comments]context: we used to deploy https://bank-vaults.dev/docs/installing/#deploy-the-mutating-webhook which did EXACTLY that:
DB_USER: 'vault:kv/data/test/my-team/my-app/meta-db#user'and the vault part would be replaced by the value from Vault.
some (admittedly crappy) helm charts require those env vars values to be set or they will just be rejected.
unfortunately...
banzaicloud, the bank-vaults developer, has been bought by Cisco as far as I can tell, the current version doesn't do this anymore: https://bank-vaults.dev/docs/installing/#deploy-the-mutating-webhook the official hashicorp agent injector works very well but has the same limitation of having to be able to set spec: template: :annotations (which some crappy charts don't allow)is there a tool or a way to achieve this, when you don't have access to spec: template: :annotations? we'd rather not have to modify the charts separately, with a patch or with Kustomize, because those deployments are done on several clusters and the chain gets pretty complicated.
this is Helm's biggest issue to me, the inability to override something that isn't part of the underlying values / templates without modifying them. if there IS a way to do that, I'm also very interested as I can't find anything about it.
submitted by /u/Le_Vagabond [link] [comments]It seems like Talos support for Raspberry Pi 5 is not quite there yet, anyone else facing this issue? Any alternatives?
https://github.com/siderolabs/talos/issues/7978
submitted by /u/mmontes11 [link] [comments]Hi, guys. I'll try to summarize: I'm installing Loki and Grafana each one in different namespaces on my k8s cluster hosted by Digital Ocean (personal cluster, short space, for study only).
I got issues to add Loki DataSouce in Grafana. I'm having 502 Bad Gateway when I'm trying to setup datasource as loki-gateway services.
Actually, the main cause is that loki gateway is trying to use a service called loki-query-frontend. However, Helm doesn't install it when I use monolothic installation (singleBinary.replicas = 1).
I have looked all helm templates and found out conditions that avoid instalation of it in such scenario (also, I found out documetation stated that as monolithic, everything should run in a single binary).
If that so, why gateway try to use other k8s service that it is not installed?
I am not an observation specialist, so I'd like so ask for some advices in order to overcome it. I'm almost convincing that helm instalation of Loki is not a good idea.
submitted by /u/mgodoy-br [link] [comments]I want to use an older version of Kubernetes, 1.14 is the first thing that comes to mind, is this available and do I need to get the source to install it?
Most importantly, if I want to use an older version, I'll need a version-specific kubectl or kubelet, can I get those?
Have mercy on a poor newbie.
submitted by /u/AgitatedLocation9082 [link] [comments]which tools to install? kubectl, minikube, kubeadm, kind?
submitted by /u/PaulGureghian11 [link] [comments]Hello, new to helm and trying to make sense of it. Was able to install ngnix, Prometheus and charts for other services that keep running. What would be the correct way to deploy something that should just run once and finish? I understand it's not a common use case as I wasn't able to find any examples. I end up with CrashLoopBackOff. Is the issues with the replicas setting? what should I set there?
submitted by /u/PressureRight2934 [link] [comments]Hi all - apologies if this is the wrong place to ask, but I had a question regarding which workload value is used in the calculation for whether or not to scale up or down. Specifically, does the autoscaler take in the summation of all the workloads resource 'requests' or resource 'limits'? I've read through docs on this, but I've yet to see a clear answer to my question.
Thanks in advance!
submitted by /u/TypeRighter6 [link] [comments]which tools to install? kubectl, minikube, kuebadm, kind?
submitted by /u/PaulGureghian11 [link] [comments]Sadly I don't have a testcluster to try this out with so I am trying to crowdsource the answer...
How do I manage the CRDs of the kube-prom-stack with FluxCD? Is it as easy as just putting them into Git or do I need any tweaks?
I have read that https://fluxcd.io/blog/2021/11/november-2021-update/#server-side-apply-has-landed means that per default FluxCD is using server-side apply. Is as such the only thing missing in the spec the following option?
spec: kustomize.toolkit.fluxcd.io/force: enabledI want to translate the following into FluxCD (and update its content with every version of course).
kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_alertmanagerconfigs.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_alertmanagers.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_podmonitors.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_probes.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_prometheusagents.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_prometheuses.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_prometheusrules.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_scrapeconfigs.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_servicemonitors.yaml kubectl apply --server-side -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/v0.73.0/example/prometheus-operator-crd/monitoring.coreos.com_thanosrulers.yaml submitted by /u/speedy19981 [link] [comments]So, I know how to set up a GPU k3s cluster.
Now, I want to add other nodes from different networks as agents in the GPU k3s cluster.
How should I do that? And what steps should the agent nodes take in order to be a part of the GPU k3s cluster?
Is there something more that needs to be done apart from server IP and token?
submitted by /u/Accomplished_Wish244 [link] [comments]