HOW CONTAINERS SUPPORT SERVICE REGISTRATION + DISCOVERY / KUBERNETES BY GOOGLE
SIX MSA PATTERNS.
The most common microservice patterns are Message-Oriented, Event-Driven, Isolated State, Replicating State, Fine-Grained (SOA), and Layered APIs.
Web Services and Business Processes were once complicated by the issue of State. By their nature, Business Processes are Stateful, in that changes occur after each step is performed. The moment of each event is measured as the clock ticks. In the early days, Web Services were always Stateless. This was slowly resolved with non-proprietary solutions such as business process Management Notation (BPMN) and Business Process Execution Language (PBEL). Yet, some Web Services execute or expose computing functions and others are executing business processes. In some cases, a clock matters and other cases, it does not.
Kristopher Sandoval sees a reason for people to be confused, noting “stateless services have managed to mirror a lot of the behavior of stateful services without technically crossing the line.” His explains, “When the state is stored by the server, it generates a session. This is stateful computing. When the state is stored by the client, it generates some kind of data that is to be used for various systems — while technically ‘stateful’ in that it references a state, the state is stored by the client so we refer to it as stateless. Sandoval writes for Nordic APIs.
STATEFUL PATTERNS AND EVI.
Traditional system design favors consistent data queries and mutating state, which is not how distributed architectures are designed. To avoid unexpected results or data corruption, a state needs to be explicitly declared or each component needs to be autonomous. Event-driven patterns provide standards to avoid side-effects of explicitly declaring a state. Message-oriented systems use a queue, while event-based also sets and enforces standards to assure that the design and behavior of messages over the queue have a timestamp. A materialized view of the state can be reconstructed by the service receiving it. It can then replay the events in order. This makes the event-based pattern ideal for EVI.
Any pattern that records time stamps is suitable. Therefore, an index of microservices should also attempt to classify whether a Service has a time-stamp, using the input of whether it is stateful as a key predictor. To start, “service discovery” is required. Enterprise Value Integration (EVI) is then able to leverage the inventory of services to track inputs, transformations, and outputs associated with each customer and each process they consume. This is vital to improve profitability, while also delivering more consistently on brand promises.
EVI is the only brand consulting firm in the world to recognize the importance of containers and serverless computing – and consistently re-engineer organizations to deliver more value.
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications offered by Google. It groups containers that make up an application into logical units for easy management and discovery.
KUBERNETES
Docker has a free open source and paid enterprise versions and is considered a simpler and more flexible container storage platform than Kubernetes. Although it is also open source, it comes from Google and is considered more intricate. Some say overly-complicated. The simplicity of Docker is illustrated through service discovery. As long as the container name is used as hostname, a container can always discover other containers on the same stack. Docker Cloud uses directional links recorded in environment variables to provides a basic service discovery functionality. The complexity of Kubernetes is illustrated through service registration and discovery. Kubernetes is predicated in the idea that a Service is a REST object. This means that a Service definition can be POSTed to the apiserver to create a new instance. Kubernetes offers Endpoints API, which is updated when a Service changes. Google explains, “for non-native applications, Kubernetes offers a virtual-IP-based bridge to Services which redirects to the backend Pods.” A group of containers that deployed together on the same host is a Kubernetes pod. Kubernetes supports domain name servers (DNS) discovery as well as environmental variables. Google strongly recommends the DNS approach.
KUBERNETES: TOP TEN LINKS
1. What is Kubernetes?
2. Kubernetes on RedHat
3. Azure Kubernetes Service (AKS)
4. IBM Cloud Kubernetes Service
5. Introduction to Kubernetes by Digital Ocean
6. Kubernetes Components
7. Understanding Kubernetes Objects
8. Kubernetes on OpenStack
9. Lessoned Learned from Using Kubernetes for One Year
10. Download Kubernetes on GitHub
CONTAINERS & CLOUD COMPUTING: TOP TEN LINKS
1. What are Containers?
2. Containers and Cloud Computing
3. Containers vs. Virtual Machines
4. What is a Linux Container?
5. Comparing Kubernetes and Docker
6. Amazon Elastic Container Service (Amazon ECS)
7. Run containers without servers with AWS Fargate
8. RedHat OpenShift Container Platform
9. Rancher Container Management Platform
10. IronWorker and Serverless Computing
CONTAINERS (by Google)
It’s a great time for organizations innovating with AI. Google recently launched Gemini, our largest and most capable AI model, followed by Gemma, a family of lightweight, state-of-the art open models built from research and technology that we used to create the Gemini models. Gemma models achieve best-in-class performance for their size (Gemma 2B and Gemma 7B) compared to other open models, and are pre-trained and equipped with instruction-tuned variants to enable research and development. The release of Gemma and our updated platform capabilities are the next phase of our commitment to making AI more open and accessible to developers on Google Cloud. Today, let’s take a look at the enhancements we’ve made to Google Kubernetes Engine (GKE) to help you serve and deploy Gemma on GKE Standard as well as Autopilot:
Integration with Hugging Face, Kaggle and Vertex AI Model Garden: If you are a GKE customer, you can deploy Gemma by starting in Hugging Face, Kaggle or Vertex AI Model Garden. This lets you easily deploy models from your preferred repositories to the infrastructure of your choice.
GKE notebook experience using Colab Enterprise: Developers who prefer an IDE-like notebook environment for their ML project can now deploy and serve Gemma using Google Colab Enterprise.
A cost-efficient, reliable and low-latency AI inference stack: Earlier this week we announced JetStream, a highly efficient AI-optimized large language model (LLM) inference stack to serve Gemma on GKE. Along with JetStream, we introduced a number of cost- and performance-efficient AI-optimized inference stacks for serving Gemma across ML Frameworks (PyTorch, JAX) powered by Cloud GPUs or Google’s purpose-built Tensor Processor Units (TPU). Earlier today we published a performance deepdive of Gemma on Google Cloud AI optimized infrastructure for training and serving generative AI workloads.
Now, whether you are a developer building generative AI applications, an ML engineer optimizing generative AI container workloads, or an infrastructure engineer operationalizing these container workloads, you can use Gemma to build portable, customizable AI applications and deploy them on GKE.
Let’s walk through each of these releases in more detail.
Hugging Face, Vertex AI Model Garden and Kaggle integrationRegardless of where you get your AI models, our goal is to make it easy for you to deploy them on GKE.
Hugging FaceEarlier this year, we signed a strategic partnership with Hugging Face, one of the preferred destinations for the AI community, to provide data scientists, ML engineers and developers with access to the latest models. Hugging Face launched the Gemma model card, allowing you to deploy Gemma from Hugging Face directly to Google Cloud. Once you click the Google Cloud option, you will be redirected to Vertex Model Garden, where you can choose to deploy and serve Gemma on Vertex AI or GKE.
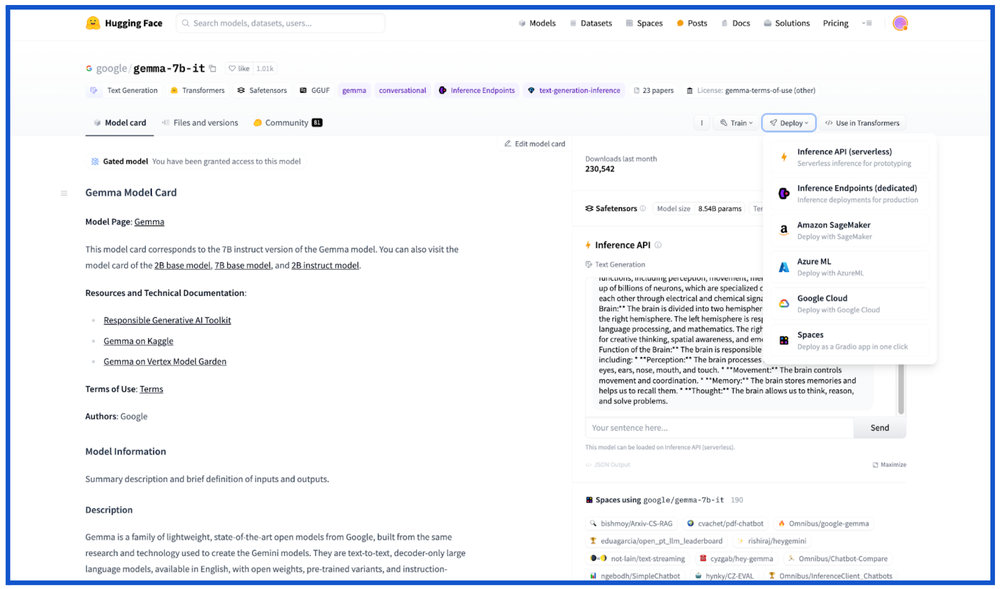 Vertex Model Garden
Vertex Model Garden
Gemma joins 130+ models in Vertex AI Model Garden, including enterprise-ready foundation model APIs, open-source models, and task-specific models from Google and third parties.
 Kaggle
Kaggle
Kaggle allows developers to search and discover thousands of trained, ready-to-deploy machine learning models in one place. The Gemma model card on Kaggle provides a number of model variations (PyTorch, FLAX, Transformers, etc) to enable an end-to-end workflow for downloading, deploying and serving Gemma on a GKE cluster. Kaggle customers can also “Open in Vertex,” which takes them to Vertex Model Garden where they can see the option to deploy Gemma either on Vertex AI or GKE as described above. You can explore real-world examples using Gemma shared by the community on Gemma's model page on Kaggle.
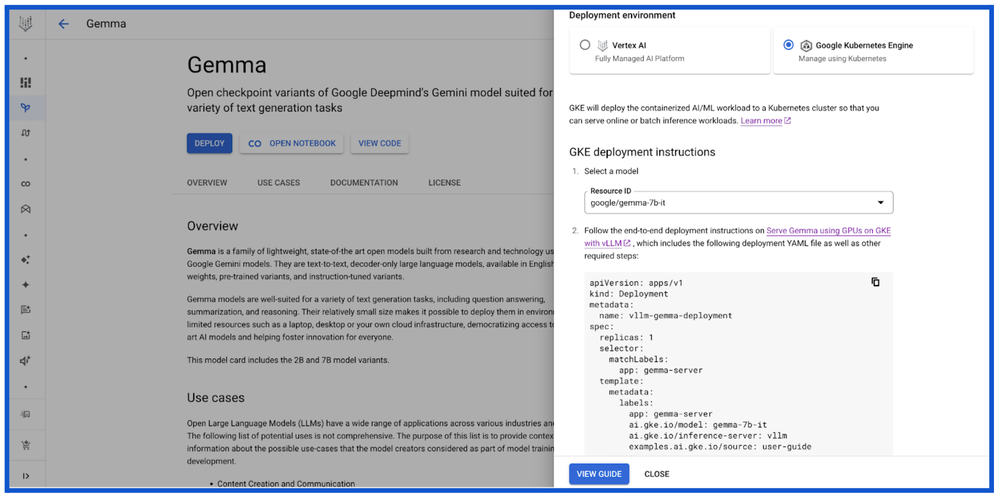
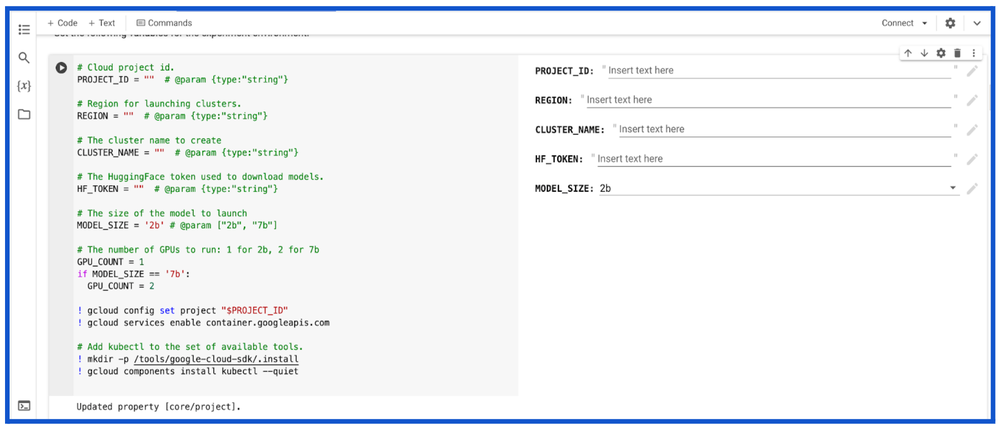
Google Colab Enterprise notebooksDevelopers, ML engineers and ML practitioners can also deploy and serve Gemma on GKE using Google Colab Enterprise notebooks via Vertex AI Model Garden. Colab Enterprise notebooks come with pre-populated instructions in the code cells, providing the flexibility to deploy and run inference on GKE using an interface that is preferred by developers, ML engineers and scientists.
 Serve Gemma models on AI-optimized infrastructure
Serve Gemma models on AI-optimized infrastructure
When running inference at scale, performance per dollar and cost of serving are critical. Powered by an AI-optimized infrastructure stack equipped with Google Cloud TPUs and GPUs, GKE enables high-performance and cost-efficient inference for a broad range of AI workloads.
“GKE empowers our ML pipelines by seamlessly integrating TPUs and GPUs, allowing us to leverage the strengths of each for specific tasks and reduce latency and inference costs. For instance, we efficiently process text prompts in batches using a large text encoder on TPU, followed by employing GPUs to run our in-house diffusion model, which utilizes the text embeddings to generate stunning images.” - Yoav HaCohen, Ph.D, Core Generative AI Research Team Lead, Lightricks
We are excited to extend these benefits to workloads that are equipped with Gemma on GKE.
 Gemma on GKE with TPUs
Gemma on GKE with TPUs
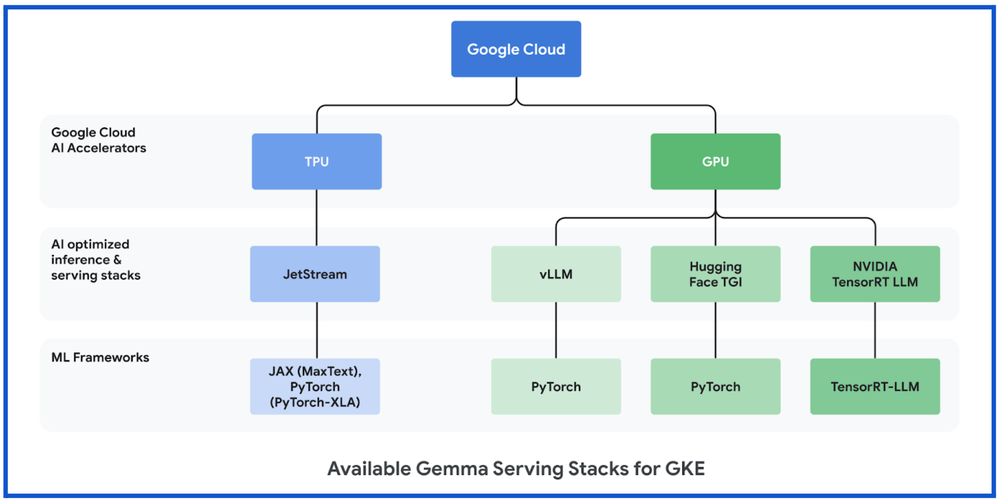
If you prefer to use Google Cloud TPU accelerators with your GKE infrastructure, several AI-optimized inference and serving frameworks also now support Gemma on Google Cloud TPUs, and already support the most popular LLMs. These include:
JetStreamFor optimizing inference performance for PyTorch or JAX LLMs on Google Cloud TPUs, we launched JetStream(MaxText) and JetStream(PyTorch-XLA), a new inference engine specifically designed for LLM inference. JetStream represents a significant leap forward in both performance and cost efficiency, offering strong throughput and latency for LLM inference on Google Cloud TPUs. JetStream is optimized for both throughput and memory utilization, providing efficiency by incorporating advanced optimization techniques such as continuous batching, int8 quantization for weights, activations and KV cache. JetStream is the recommended TPU inference stack from Google.
Get started with JetStream inference for Gemma on GKE and Google Cloud TPUs with this tutorial.
Gemma on GKE with GPUsIf you prefer to use Google Cloud GPU accelerators with your GKE infrastructure, several AI-optimized inference and serving frameworks also now support Gemma on Google Cloud GPUs, and already support the most popular LLMs. These include:
vLLMUsed to increase serving throughput for PyTorch generative AI users, vLLM is a highly optimized open-source LLM serving framework. vLLM includes features such as:
An optimized transformer implementation with PagedAttention
Continuous batching to improve the overall serving throughput
Tensor parallelism and distributed serving on multiple GPUs
Get started with vLLM for Gemma on GKE and Google Cloud GPUs with this tutorial.
Text Generation Inference (TGI)Designed to enable high-performance text generation, Text Generation Inference (TGI) is a highly optimized open-source LLM serving framework from Hugging Face for deploying and serving LLMs. TGI includes features such as continuous batching to improve overall serving throughput, and tensor parallelism and distributed serving on multiple GPUs.
Get started with Hugging Face Text Generation Inference for Gemma on GKE and Google Cloud GPUs with this tutorial.
TensorRT-LLMTo optimize inference performance of the latest LLMs on Google Cloud GPU VMs powered by NVIDIA Tensor Core GPUs, customers can use NVIDIA TensorRT-LLM, a comprehensive library for compiling and optimizing LLMs for inference. TensorRT-LLM supports features like paged attention, continuous in-flight batching, and others.
Get started with NVIDIA Triton and TensorRT LLM backend on GKE and Google Cloud GPU VMs powered by NVIDIA Tensor Core GPUs with this tutorial.
Train and serve AI workloads your wayWhether you’re a developer building new gen AI models with Gemma, or choosing infrastructure on which to train and serve those models, Google Cloud provides a variety of options to meet your needs and preferences. GKE provides a self-managed, versatile, cost-effective, and performant platform on which to base the next generation of AI model development.
With integrations into all the major AI model repositories (Vertex AI Model Garden, Hugging Face, Kaggle and Colab notebooks), and support for both Google Cloud GPU and Cloud TPU, GKE offers several flexible ways to deploy and serve Gemma. We look forward to seeing what the world builds with Gemma and GKE. To get started, please refer to the user guides on the Gemma on GKE landing page.
Everywhere you look, there is an undeniable excitement about AI. We are thrilled, but not surprised, to see Google Cloud’s managed containers taking a pivotal role in this world-shaping transformation. We’re pleased to share announcements from across our container platform that will help you accelerate AI application development and increase AI workload efficiency so you can take full advantage of the promise of AI, while also helping you continue to drive your modernization efforts.
The opportunity: AI and containersAI visionaries are pushing the boundaries of what’s possible, and platform builders are making those visions a scalable reality. The path to success builds on your existing expertise and infrastructure, not throwing away what you know. These new workloads demand a lot out of their platforms in the areas of:
Velocity: with leaders moving rapidly from talking about AI to deploying AI, time to market is more important than ever.
Scale: many of today’s systems were designed with specific scalability challenges in mind. Previous assumptions, no matter if you are a large model builder or looking to tune a small model for your specific business needs, have changed significantly.
Efficiency goals: AI’s inherent fluidity — such as shifting model sizes and evolving hardware needs — is changing how teams think about the cost and performance of both training and serving. Companies need to plan and measure at granular levels, tracking the cost per token instead of cost per VM. Teams that are able to measure and speak this new language are leading the market.
Containers serve the unique needs of AIWe’ve poured years of our insights and best practices into Google Cloud’s managed container platform and it has risen to the occasion of disruptive technology leaps of the past. And considering the aforementioned needs of AI workloads, the platform’s offerings — Cloud Run and Google Kubernetes Engine (GKE) — are ideally situated to meet the AI opportunity because they can:
Abstract infrastructure away: As infrastructure has changed, from compute to GPU time-sharing to TPUs, containers have allowed teams to take advantage of new capabilities on their existing platforms.
Orchestrate workloads: Much has changed from containers’ early days of being only used for running stateless workloads. Today, containers are optimized for a wide variety of workloads with complexity hidden from both users and platform builders. At Google, we use GKE for our own breakthrough AI products like Vertex AI, and to unlock the next generation of AI innovation with Deepmind.
Support extensibility: Kubernetes’ extensibility has been critical to its success, allowing a rich ecosystem to flourish, supporting user choice and enabling continued innovation. These characteristics now support the rapid pace of innovation and flexibility that users need in the AI era.
Cloud Run and GKE power Google products, as well as a growing roster of leading AI companies including Anthropic, Assembly AI, Cohere, and Salesforce that are choosing our container platform for its reliability, security, and scalability.
Our managed container platform provides three distinct approaches to help you move to implementation:
Solutions to get AI projects running quickly;
The ability to deploy customer AI workloads on GKE; and
Streamlined day-two operations across any of your enterprise deployments.
Cloud Run for an easy AI starting pointCloud Run has always been a great solution for getting started quickly, offloading operational burden from your platform team and giving developers scalable, easy-to-deploy resources — without sacrificing enterprise-grade security or visibility.
Today, we are pleased to announce Cloud Run application canvas, designed to generate, modify and deploy Cloud Run applications. We’ve added integrations to services such as Vertex AI, simplifying the process of consuming Vertex AI generative APIs from Cloud Run services in just a few clicks. There are also integrations for Firestore, Memorystore, and Cloud SQL, as well as load balancing. And we’ve taken the experience one step further and integrated Gemini Cloud Assist, which provides AI assistance to help cloud teams design, operate, and optimize application lifecycles. Gemini in Cloud Run application canvas lets you describe the type of application you want to deploy with natural language, and Cloud Run will create or update those resources in a few minutes.
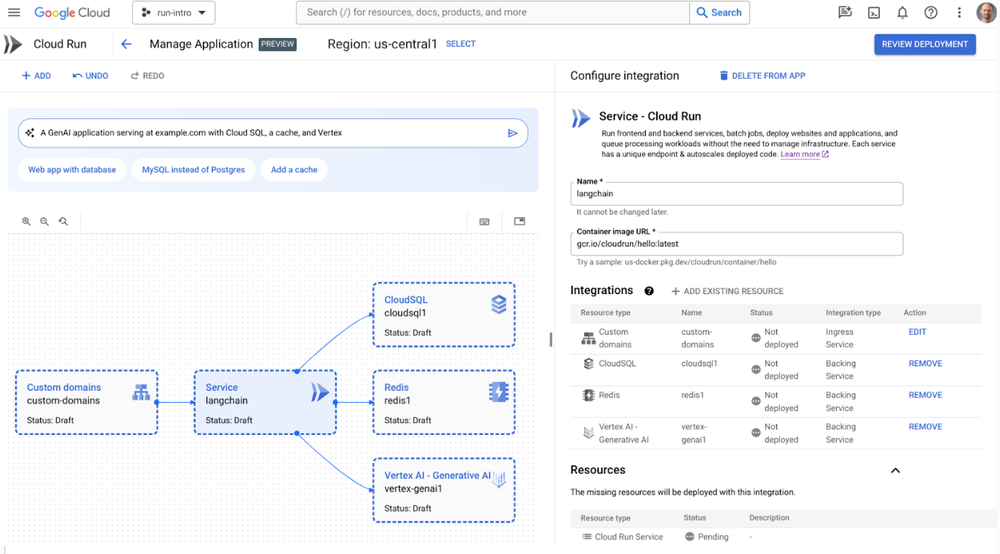
Cloud Run's application canvas showcasing a gen AI application
The velocity, scale, and efficiency you get from Cloud Run makes it a great option for building AI workloads. To help you get AI applications to market even faster, we’re pleased to announce Cloud Run support for integration with LangChain, a powerful open-source framework for building LLM-based applications. This support makes Cloud Run the easiest way to deploy and scale LangChain apps, with a developer-friendly experience.
“We researched alternatives, and Cloud Run is the easiest and fastest way to get your app running in production." - Nuno Campos, founding engineer, LangChain

Creating and deploying a LangChain application to Cloud Run
GKE for training and inferenceFor customers who value an open, portable, cloud-native, and customizable platform for their AI workloads, GKE is ideal. The tremendous growth in AI adoption continues to be reflected in how customers are using our products : Over the last year, the use of GPUs and TPUs on Google Kubernetes Engine has grown more than 900%.
To better meet the needs of customers transforming their businesses with AI, we've built innovations that let you train and serve the very largest AI workloads, cost effectively and seamlessly. Let's dive into each of those three: scale, cost efficiency, and ease of use.
Large-scale AI workloadsMany recent AI models demonstrate impressive capabilities, thanks in part to their very large size. As your AI models become larger, you need a platform that's built to handle training and serving massive AI models. We continue to push the limits of accelerator-optimized hardware to make GKE an ideal home for your large-scale AI models:
Cloud TPU v5p, which we announced in December and is now generally available, is our most powerful and scalable TPU accelerator to date. By leveraging TPU v5p on GKE, Google Cloud customer, Lightricks has achieved a remarkable 2.5X speedup in training their text-to-image and text-to-video models compared to TPU v4.
A3 Mega, which we announced today, is powered by NVIDIA's H100 GPUs and provides 2x more GPU to GPU networking bandwidth than A3, accelerating the time to train the largest AI models with GKE. A3 Mega will be generally available in the coming weeks.
Training the largest AI models often requires scaling far beyond a physical TPU. To enable continued scaling, last year we announced multi-slice training on GKE, which is generally available, enabling full-stack, cost-effective, large-scale training with near-linear scaling up to tens of thousands of TPU chips. We demonstrated this capability by training a single AI model using over 50,000 TPU v5e chips while maintaining near-ideal scaling performance.
Cost-efficient AI workloadsAs AI models continue to grow, customers face many challenges to scaling in a cost effective way. For example, AI container images can be massive, causing cold start times to balloon. Keeping AI inference latency low requires overprovisioning to handle unpredictable load, but slow cold-start times require compensating by overprovisioning even more. All of this creates under-utilization and unnecessary costs.
GKE now supports container and model preloading, which accelerates workload cold start — enabling you to improve GPU utilization and save money while keeping AI inference latency low. When creating a GKE node pool, you can now preload a container image or model data in new nodes to achieve much faster workload deployment, autoscaling, and recovery from disruptions like maintenance events. Vertex AI's prediction service, which is built on GKE, found container preloading resulted in much faster container startup:
“Within Vertex AI's prediction service, some of our container images can be quite large. After we enabled GKE container image preloading, our 16GB container images were pulled up to 29x faster in our tests.” – Shawn Ma, Software Engineer, Vertex AI
For AI workloads that have highly variable demand such as low-volume inference or notebooks, a GPU may sit idle much of the time. To help you run more workloads on the same GPU, GKE now supports GPU sharing with NVIDIA Multi-Process Service (MPS). MPS enables concurrent processing on a single GPU, which can improve GPU efficiency for workloads with low GPU resource usage, reducing your costs.
To maximize the cost efficiency of AI accelerators during model training, it's important to minimize the time an application is waiting to fetch data. To achieve this, GKE supports GCS FUSE read caching, which is now generally available. GCS FUSE read caching uses a local directory as a cache to accelerate repeat reads for small and random I/Os, increasing GPU and TPU utilization by loading your data faster. This reduces the time to train a model and delivers up to 11x more throughput.
Ease of use for AI workloadsWith GKE, we believe achieving AI scale and cost efficiency shouldn't be difficult. GKE makes obtaining GPUs for AI training workloads easy by using Dynamic Workload Scheduler, which has been transformative for customers like Two Sigma:
“Dynamic Workload Scheduler improved on-demand GPU obtainability by 80%, accelerating experiment iteration for our researchers. Leveraging the built-in Kueue and GKE integration, we were able to take advantage of new GPU capacity in Dynamic Workload Scheduler quickly and save months of development work.” – Alex Hays, Software Engineer, Two Sigma
For customers who want Kubernetes with a fully managed mode of operation, GKE Autopilot now supports NVIDIA H100 GPUs, TPUs, reservations, and Compute Engine committed use discounts (CUDs).
Traditionally, using a GPU required installing and maintaining the GPU driver on each node. However, GKE can now automatically install and maintain GPU drivers, making GPUs easier to use than ever before.
The enterprise platform for Day Two and beyondGoogle Cloud’s managed container platform helps builders get started and scale up AI workloads. But while AI workloads are a strategic priority, there remains critical management and operations work in any enterprise environment. That’s why we continue to launch innovative capabilities that support all modern enterprise workloads.
This starts with embedding AI directly into our cloud. Gemini Cloud Assist helps you boost Day-two operations by:
Optimizing costs: Gemini will help you identify and address dev/test environments left running, forgotten clusters from experiments, and clusters with excess resources.
Troubleshooting: get a natural language interpretation of the logs in Cloud Logging.
Synthetic Monitoring: using natural language, you can now describe the target and user journey flows that you'd like to test, and Gemini will generate a custom test script that you can deploy or configure further based on your needs.
And it’s not just Day-two operations, Gemini Cloud Assist can help you deploy three-tier architecture apps, understand Terraform scripts and more, drastically simplifying design and deployment.
While AI presents a thrilling new frontier, we have not lost focus on the crucial elements of a container platform that serves modern enterprises. We’ve continued to invest in foundational areas that ensure the stability, security, and compliance of your cloud-native applications and were excited to introduce the following preview launches:
GKE threat detection is powered by Security Command Center (SCC), and surfaces threats affecting your GKE clusters in near real-time by continuously monitoring GKE audit logs.
GKE compliance, a fully managed compliance service that automatically delivers end-to-end coverage from the cluster to the container, scanning for compliance against the most important benchmarks. Near-real-time insights are always available in a centralized dashboard and we produce compliance reports automatically for you.
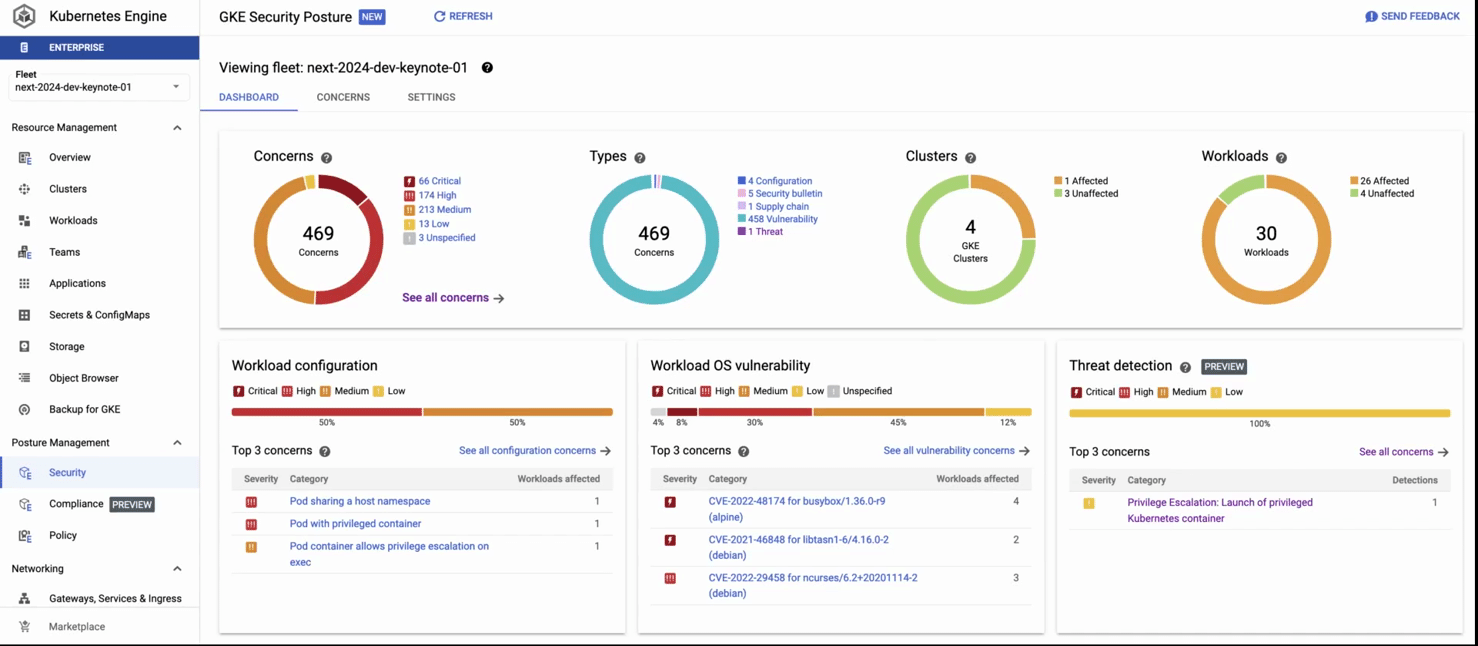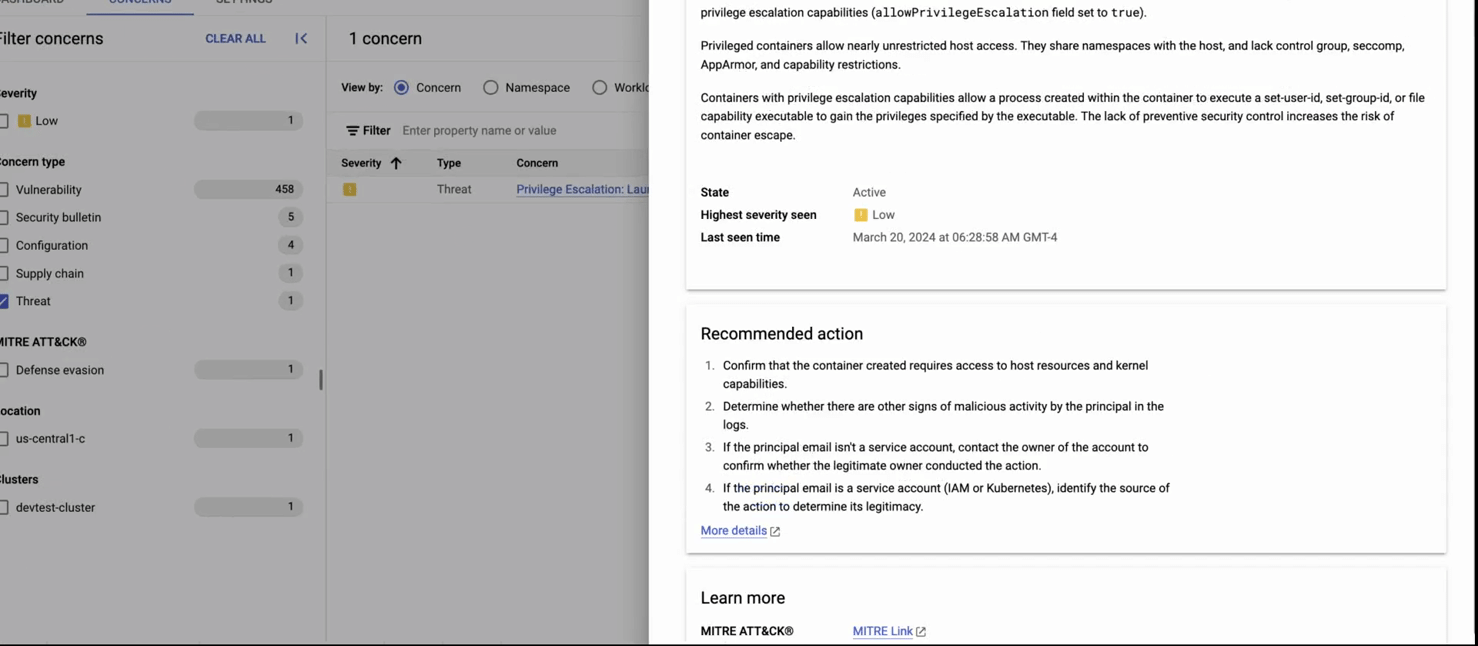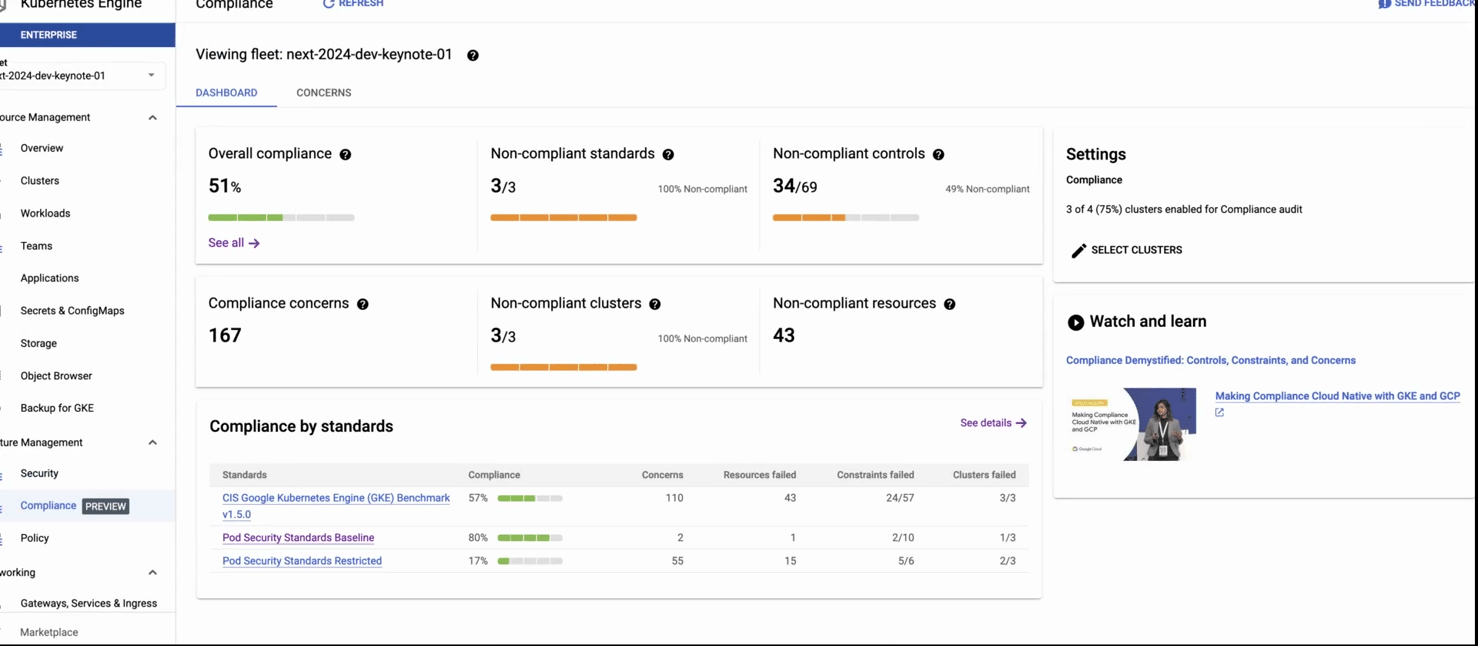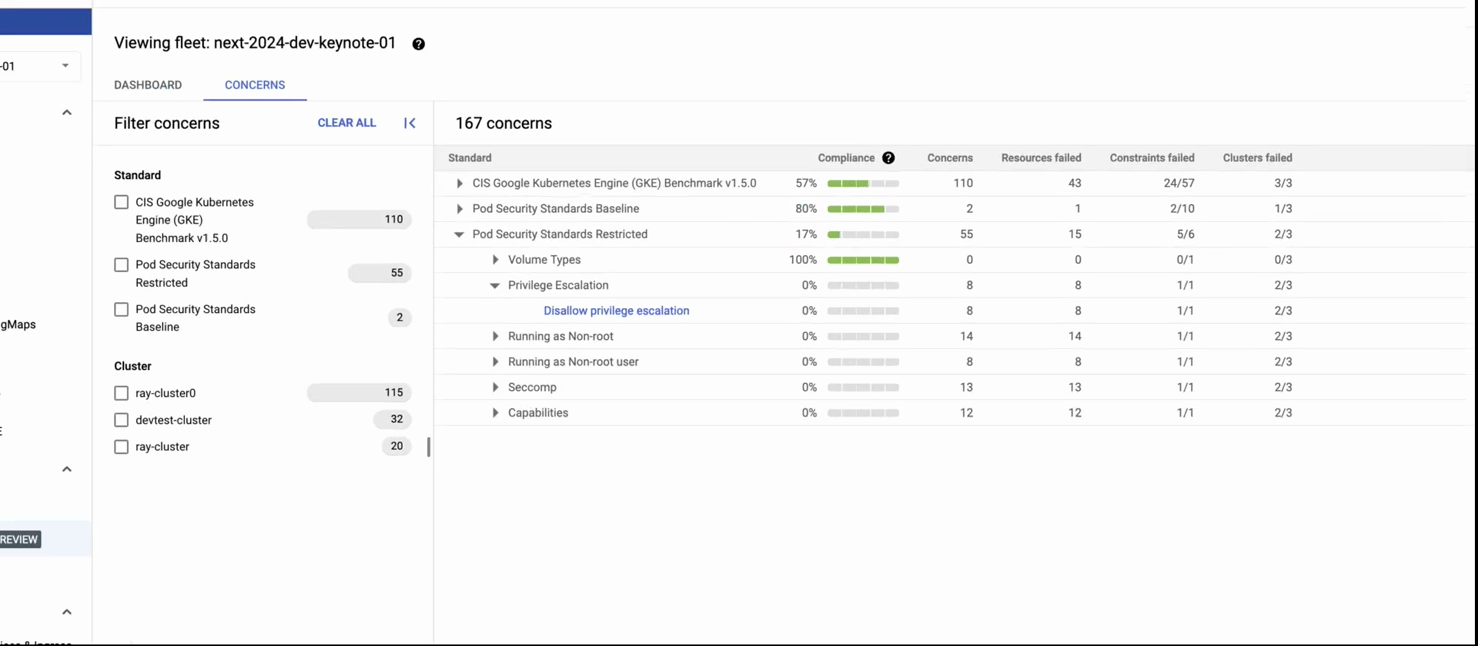
This recording shows: 1) the GKE security posture dashboard, 2) clicking on the threat detection panel, and 3) getting details about a detected threat (creation of a pod with privileged containers). In the second part of the recording, we 4)navigate to the compliance dashboard where we see comprehensive compliance assessments for industry standards, then 5) we click on the concerns tab, where we see detailed reporting by each standard. 6) Finally we see details on the compliance constraints (checks) that failed (in this case, privilege escalation) and recommended remediation.
Let’s get to workThe urgency of the AI moment is permeating every aspect of technology, and data scientists, researchers, engineers, and developers are looking to platform builders to put the right resources in their hands. We’re ready to play our part in your success, delivering scalable, efficient, and secure container resources that fit seamlessly into your existing enterprise. We’re giving you three ways to get started:
For building your first AI application with Google Cloud, try Cloud Run and Vertex AI.
To learn how to serve an AI model, get started serving Gemma, Google's family of lightweight open models, using Hugging Face TGI, vLLM, or TensorRT-LLM.
If you’re ready to try GKE AI with a Retri Augmented Generation (RAG) pattern with an open model or AI ecosystem integrations such as Ray, try GKE Quick Start Solutions.
Google Cloud has been steadfast in its commitment to being the best place to run containerized workloads since the 2015 launch of Google Container Engine. 2024 marks a milestone for open source Kubernetes, which celebrates its 10th anniversary in June. We’d like to give kudos to the community that has powered its immense success. According to The Cloud Native Computing Foundation (CNCF), the project now boasts over 314,000 code commits, by over 74,000 contributors. The number of organizations contributing code has also grown from one to over 7,800 in the last 10 years. These contributions, as well as the enterprise scale, operational capability, and accessibility offered by Google Cloud’s managed container platform, have constantly expanded the usefulness of containers and Kubernetes for large numbers of organizations. We’re excited to work with you as you build for the next decade of AI and beyond!
Google Cloud Next ‘24 is around the corner, and it’s the place to be if you’re serious about cloud development! Starting April 9 in Las Vegas, this global event promises a deep dive into the latest updates, features, and integrations for the services of Google Cloud’s managed container platform, Google Kubernetes Engine (GKE) and Cloud Run. From effortlessing scaling and optimizing AI models to providing tailored environments across a range of workloads — there’s a session for everyone. Whether you’re a seasoned cloud pro or just starting your serverless journey, you can expect to learn new insights and skills to help you deliver powerful, yet flexible, managed container environments in this next era of AI innovation.
Don’t forget to add these sessions to your event agenda — you won’t want to miss them.
Google Kubernetes Engine sessionsOPS212: How Anthropic uses Google Kubernetes Engine to run inference for Claude Learn how Anthropic is using GKEs resource management and scaling capabilities to run inference for Claude, its family of foundational AI models, on TPU v5e.
OPS200: The past, present, and future of Google Kubernetes Engine Kubernetes is turning 10 this year in June! Since its launch, Kubernetes has become the de facto platform to run and scale containerized workloads. The Google team will reflect on the past decade, highlight how some of the top GKE customers use our managed solution to run their businesses, and what the future holds.
DEV201: Go from large language model to market faster with Ray, Hugging Face, and LangChain Learn how to deploy Retri-Augmented Generation (RAG) applications on GKE using open-source tools and models like Ray, HuggingFace, and LangChain. We’ll also show you how to augment the application with your own enterprise data using the pgvector extension in Cloud SQL. After this session, you’ll be able to deploy your own RAG app on GKE and customize it.
DEV240: Run workloads not infrastructure with Google Kubernetes Engine Join this session to learn how GKE's automated infrastructure can simplify running Kubernetes in production. You’ll explore cost -optimization, autoscaling, and Day 2 operations, and learn how GKE allows you to focus on building and running applications instead of managing infrastructure.
OPS217: Access traffic management for your fleet using Google Kubernetes Engine Enterprise Multi-cluster and tenant management are becoming an increasingly important topic. The platform team will show you how GKE Enterprise makes operating a fleet of clusters easy, and how to set up multi-cluster networking to manage traffic by combining it with the Kubernetes Gateway API controllers for GKE.
OPS304: Build an internal developer platform on Google Kubernetes Engine Enterprise Internal Developers Platforms (IDP) are simplifying how developers work, enabling them to be more productive by focusing on providing value and letting the platform do all the heavy lifting. In this session, the platform team will show you how GKE Enterprise can serve as a great starting point for launching your IDP and demo the GKE Enterprise capabilities that make it all possible.
Cloud Run sessionsDEV205: Cloud Run – What's new Join this session to learn what's new and improved in Cloud Run in two major areas — enterprise architecture and application management.
DEV222: Live-code an app with Cloud Run and Flutter During this session, see the Cloud Run developer experience in real time. Follow along as two Google Developer Relations Engineers live-code a Flutter application backed by Firestore and powered by an API running on Cloud Run.
DEV208: Navigating Google Cloud - A comprehensive guide for website deploymentLearn about the major options for deploying websites on Google Cloud. This session will cover the full range of tools and services available to match different deployment strategies — from simple buckets to containerized solutions to serverless platforms like Cloud Run.
DEV235: Java on Google Cloud — The enterprise, the serverless, and the native In this session, you’ll learn how to deploy Java Cloud apps to Google Cloud and explore all the options for running Java workloads using various frameworks.
DEV237: Roll up your sleeves - Craft real-world generative AI Java in Cloud Run In this session, you’ll learn how to build powerful gen AI applications in Java and deploy them on Cloud Run using Vertex AI and Gemini models.
DEV253: Building generative AI apps on Google Cloud with LangChain Join this session to learn how to combine the popular open-source framework LangChain and Cloud Run to build LLM-based applications.
DEV228: How to deploy all the JavaScript frameworks to Cloud Run Have you ever wondered if you can deploy JavaScript applications to Cloud Run? Find out in this session as one Google Cloud developer advocate sets out to prove that you can by deploying as many JavaScript frameworks to Cloud Run as possible.
DEV241: Cloud-powered, API-first testing with Testcontainers and Kotlin Testcontainers is a popular API-first framework for testing applications. In this session, you’ll learn how to use the framework with an end-to-end example that uses Kotlin code in BigQuery and PubSub, Cloud Build, and Cloud Run to improve the testing feedback cycle.
ARC104: The ultimate hybrid example - A fireside chat about how Google Cloud powers (part of) AlphabetJoin this fireside chat to learn about the ultimate hybrid use case — running Alphabet services in some of Google Cloud’s most popular offerings. Learn how Alphabet leverages Google Cloud runtimes like GKE, why it doesn’t run everything on Google Cloud, and the reason some products run partially on cloud.
DEV202: Accelerate your AI with ServerlessServerless platforms and generative AI applications are a great match. In this talk you'll learn how Google Cloud's pay-as-you-go model for serverless runtimes can be used to supplement your generative AI model with function calling.
Firebase sessionsDEV221: Use Firebase for faster, easier mobile application development Firebase is a beloved platform for developers, helping them develop apps faster and more efficiently. This session will show you how Firebase can accelerate application development with prebuilt backend services, including authentication, databases and storage.
DEV243: Build full stack applications using Firebase and Google CloudFirebase and Google Cloud can be used together to build and run full stack applications. In this session, you’ll learn how to combine these two powerful platforms to enable enterprise-grade applications development and create better experiences for users.
DEV107: Make your app super with Google Cloud FirebaseLearn how Firebase and Google Cloud are the superhero duo you need to build enterprise-scale AI applications. This session will show you how to extend Firebase with Google Cloud using Gemini — our most capable and flexible AI model yet — to build, secure, and scale your AI apps.
DEV250: Generative AI web development with AngularIn this session, you’ll explore how to use Angular v18 and Firebase hosting to build and deploy lightning-fast applications with Google's Gemini generative AI.
See you at the show!
Google Kubernetes Engine (GKE) offers two different ways to perform service discovery and DNS resolution: the in-cluster kube-dns functionality, and GCP managed Cloud DNS. Either approach can be combined with the performance-enhancing NodeLocal DNSCache add-on.
New GKE Autopilot clusters use Cloud DNS as a fully managed DNS solution for your GKE Autopilot clusters without any configuration required on your part. But for GKE Standard clusters, you have the following DNS provider choices:
Kube-dns (default)
Cloud DNS - configured for either cluster-scope or VPC scope, and
Install and run your own DNS (like Core DNS)
In this blog, we break down the differences between the DNS providers for your GKE Standard clusters, and guide you to the best solution for your specific situation.
Kube-DNS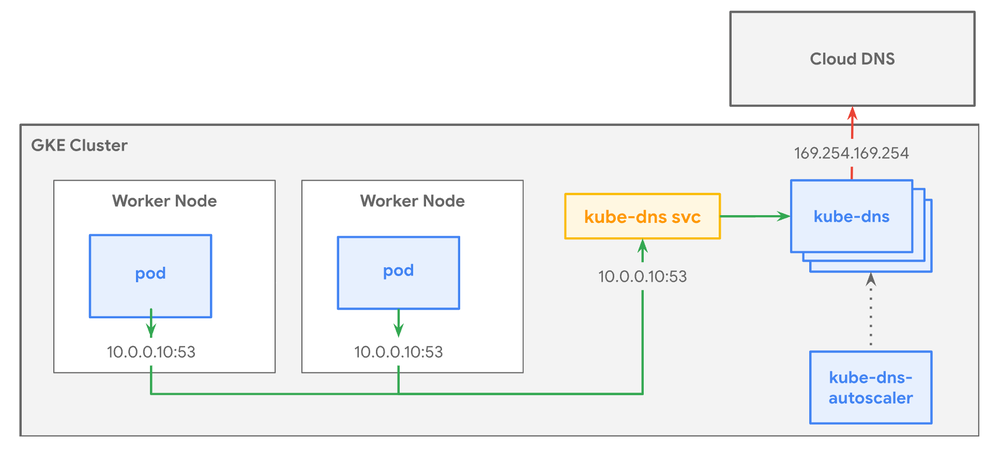
kube-dns is the default DNS provider for Standard GKE clusters, providing DNS resolution for services and pods within the cluster. If you select this option, GKE deploys the necessary kube-dns components such as Kube-dns pods, Kube-dns-autoscaler, Kube-dns configmap and Kube-dns service in the kube-system namespace.
kube-dns is the default DNS provider for GKE Standard clusters and the only DNS provider for Autopilot clusters running versions earlier than 1.25.9-gke.400 and 1.26.4-gke.500.
Kube-dns is a suitable solution for workloads with moderate DNS query volumes that have stringent DNS resolution latency requirements (e.g. under ~2-4ms). Kube-dns is able to provide low latency DNS resolution for all DNS queries as all the DNS resolutions are performed within the cluster.
If you notice DNS timeouts or failed DNS resolutions for bursty workload traffic patterns when using kube-dns, consider scaling the number of kube-dns pods, and enabling NodeLocal DNS cache for the cluster. You can scale the number of kube-dns pods beforehand using Kube-dns autoscaler, and manually tuning it to the cluster's DNS traffic patterns. Using kube-dns along with Nodelocal DNS cache (discussed below) also reduces overhead on the kube-dns pods for DNS resolution of external services.
While scaling up kube-dns and using NodeLocal DNS Cache(NLD) helps in the short term, it does not guarantee reliable DNS resolution during sudden traffic spikes. Hence migrating to Cloud DNS provides a more robust and long-term solution for improved reliability of DNS resolution consistently across varying DNS query volumes. You can update the DNS provider for your existing GKE Standard from kube-dns to Cloud DNS without requiring to re-create your existing cluster.
For logging the DNS queries when using kube-dns, there is manual effort required in creating a new kube-dns debug pod with log-queries enabled.
Cloud DNSCloud DNS is a Google-managed service that is designed for high scalability and availability. In addition, Cloud DNS elastically scales to adapt to your DNS query volume, providing consistent and reliable DNS query resolution regardless of traffic volume. Cloud DNS simplifies your operations and minimizes operational overhead since it is a Google managed service and does not require you to maintain any additional infrastructure. Cloud DNS supports dns resolutions across the entire VPC, which is something not currently possible with kube-dns.
Also, while using Multi Cluster Services (MCS) in GKE, Cloud DNS provides DNS resolution for services across your fleet of clusters.
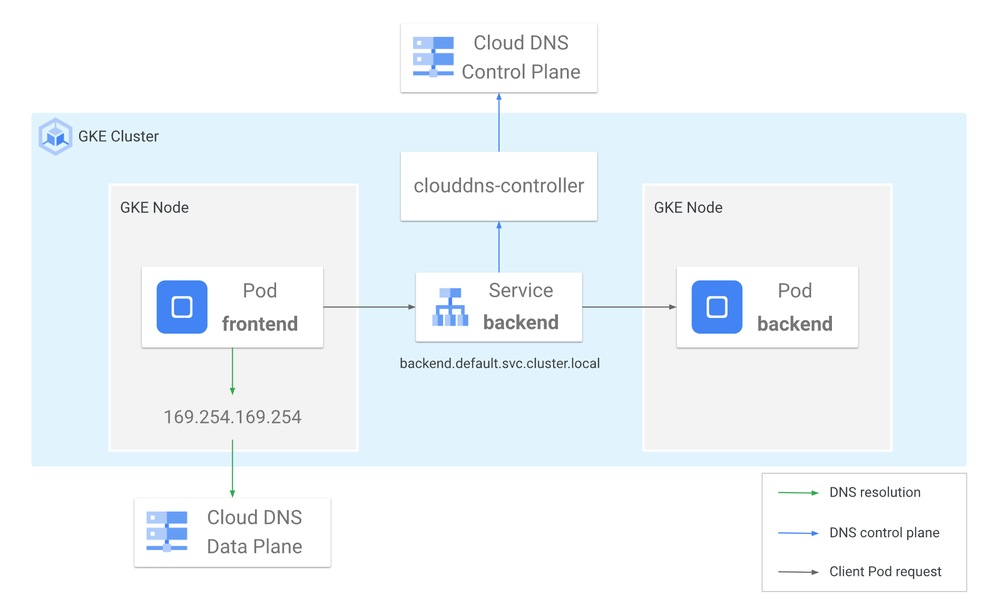
Unlike kube-dns, Google Cloud’s hosted DNS service Cloud DNS provides Pod and Service DNS resolution that auto-scales and offers a 100% service-level agreement, reducing DNS timeouts and providing consistent DNS resolution latency for heavy DNS workloads.
Cloud DNS also integrates with Cloud Monitoring, giving you greater visibility into DNS queries for enhanced troubleshooting and analysis.
The Cloud DNS controller automatically provisions DNS records for pods and services in Cloud DNS for ClusterIP, headless and external name services.
You can configure Cloud DNS to provide GKE DNS resolution in either VPC or Cluster (the default) scope. With VPC scope, the DNS records are resolvable with the entire VPC. This is achieved with the private DNS zone that gets created automatically. With Cluster scope, the DNS records are resolvable only within the cluster. The Cluster scope can be extended with Additive VPC Scope to make headless Services resolvable from other resources in the VPC.
While Cloud DNS offers enhanced features, it does come with usage-based costs. You save on compute costs and overhead by removing kube-dns pods when using Cloud DNS. Considering the typical cluster size workload traffic patterns, Cloud DNS is usually more cost effective than running kube-dns
You can migrate clusters from kube-dns to Cloud DNS cluster scope without downtime or changes to your applications. The reverse (migrating from Cloud DNS to kube-dns) is not a seamless operation.
NodeLocal DNSCache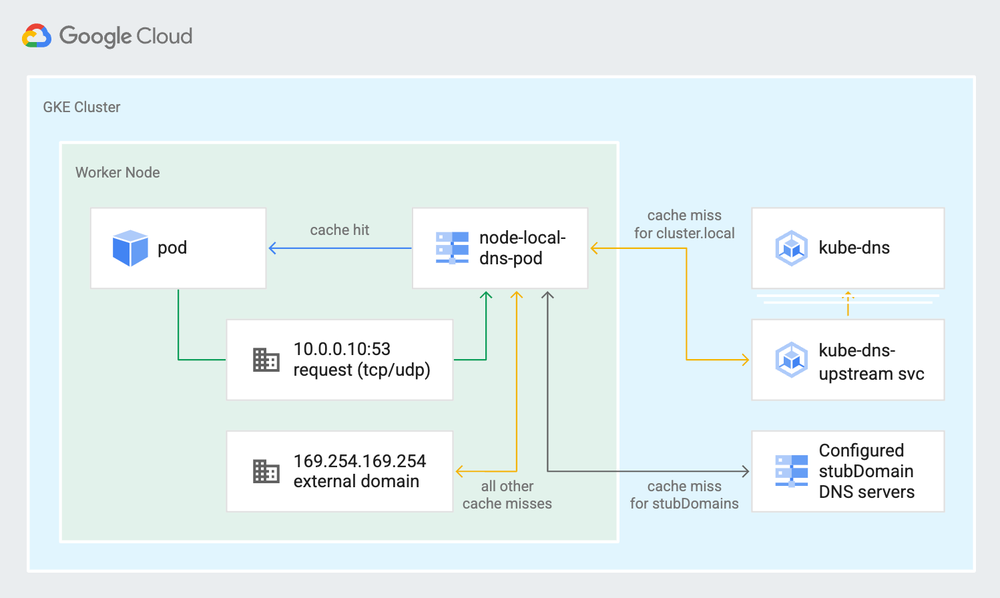
NodeLocal DNSCache is a GKE add-on that you can run in addition to kube-dns or Cloud DNS. The node-local-dns pod gets deployed on the GKE nodes after the option has been enabled (subject to a node upgrade procedure).
Nodelocal DNS Cache (NLD) helps to reduce the average DNS resolution times by resolving the DNS requests locally on the same nodes as the pods, and only forwards requests that it cannot resolve to the other DNS servers in the cluster. This is a great fit for clusters that have heavy internal DNS query loads.
Enable NLD during maintenance windows. Please note that node pools must be re-created for this change to take effect.
Final thoughtsThe choice of DNS provider for your GKE Standard cluster has implications for the performance and reliability, in addition to your operations and overall service discovery architecture. Hence, it is crucial for GKE Standard users to understand their DNS options taking into account their application and architecture objectives. Standard GKE clusters allow you to use either kube-dns or Cloud DNS as your DNS provider, allowing you to optimize for either low latency DNS resolution or a simple, scalable and reliable DNS solution for GKE Standard clusters. You can learn more about DNS for your GKE cluster from the GKE documentation . If you have any further questions, feel free to contact us.
We thank the Google Cloud team member who contributed to the blog: Selin Goksu, Technical Solutions Developer, Google
KUBERNETES (by Reddit)
This monthly post can be used to share Kubernetes-related job openings within your company. Please include:
Name of the company Location requirements (or lack thereof) At least one of: a link to a job posting/application page or contact detailsIf you are interested in a job, please contact the poster directly.
Common reasons for comment removal:
Not meeting the above requirements Recruiter post / recruiter listings Negative, inflammatory, or abrasive tone submitted by /u/gctaylor [link] [comments]What are you up to with Kubernetes this week? Evaluating a new tool? In the process of adopting? Working on an open source project or contribution? Tell /r/kubernetes what you're up to this week!
submitted by /u/gctaylor [link] [comments]
![[link]](https://i.redd.it/7u8mrhgl4eo51.jpg){kind=link}

Kubernetes v1.30 will be released tomorrow (April 17th). Sysdig overviews about half of its 58 new and improved features. Their Editor’s pick includes Memory Swap Support, Structured Authorization Configuration, and CEL for Admission Control.
submitted by /u/dshurupov [link] [comments]I've been trying to deploy my infrastructure both on K8s and Nomad (+ Consul).
The only benefit I see, that covers up for greater complexity of K8s, is the availability of managed service providers (GKE/EKS). Which makes things easier.
But Nomad seems to fit my use-case of 8-10 services deployed behind a proxy and load balancer, and is so much easier to setup and use.
I've seen a lot of people agreeing that Nomad is more straight-forward, at least for developers who don't want to invest too much time in infrastructure. But there is still hesitance in wider adoption of Nomad.
Is it largely the unavailability of a managed Nomad (or HashiStack) provider who can run the scripts on your behalf, or some other reason?
I want to understand the primary justifications behind why you as current K8 users will not adopt Nomad.
Thanks ❤️
submitted by /u/mrinalwahal [link] [comments] 
I created an app for developers and devOps engineers called Snipman.io >>> https://snipman.io
It is a self hosted code snippet management app (currently free to download on Mac and Windows) that basically lets you store snippets by snippet types. I primarily created it because I found myself creating a lot of text files for small code snippets for different devOps tools and technologies for e.g AWS, GCP, Terraform, Kubernetes, Docker etc. This not only resulted in a lot of clutter but also a pain when it came to searching. My goal was to create something that would allow all the commands, configs and random snippets to be stored in a central repo locally and then have the ability to search them quickly. I think my app helps achieve all of that in through an elegant and simple to use GUI based tool.I hope all the devOps engineers here find it useful!
{kind=link}
submitted by /u/dev_user1091 [link] [comments]If I want to deploy a app to a Kubernetes cluster where all connections to any port on a IP are sent to service that forwards it to the same incoming port on the pods and keeps the connection to the same pod how would I go about out that?
I want to deploy several instances of HAProxy but I was thinking that I may need another instance of HAProxy / LoxiLB even in front of that in order to distribute traffic to the Kubernetes hosted HAProxy deployments with a single static public IPv4.
submitted by /u/oddkidmatt [link] [comments]I'm deploying longhorn with the following modified chart settings:
defaultSettings: defaultDataLocality: strict-local defaultReplicaCount: "3" nodeDownPodDeletionPolicy: delete-both-statefulset-and-deployment-pod taintToleration: node-role.kubernetes.io/master=true:NoSchedule longhornDriver: tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Equal value: "true" longhornManager: tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Equal value: "true" persistence: defaultClassReplicaCount: "3" defaultDataLocality: best-effort migratable: "True"I'm trying to understand what are the differences between defaultSettings.defaultDataLocality and persistence.defaultDataLocality. My goal is to make sure the node does not have more than 2 replicas, so if I cordon the node, the services continue to work properly.
Reference:
submitted by /u/MuscleLazy [link] [comments]Hi folks, I've installed minikube with colima docker daemon on osx and was playing around with some monitoring tool which I forgot where I installed it from. It uses image like "rancher/mirrored-pause:3.6" and named the docker container with "k8s_POD_...".
How do I delete these, I've tried nuking my minikube and running "docker rm $(docker ps -a -q)", no luck.
submitted by /u/hardcoresoftware [link] [comments]I need to expose an application using a service type Loadbalancer. Previously, I was using ingress-nginx, but it's only one service, where there's no need for advanced routing. How can I secure this IP address? Would appreciate the community's help.
Edit: Just to clarify on the Q. I'm trying not to use any ingress or ingress controller for my use case. A simple Loadbalancer service which generates a public IP, that can handle traffic on HTTPs port (also terminating HTTPs before forwarding the traffic to the container).
submitted by /u/vivekbytes [link] [comments]https://blog.kftray.app/kubectl-port-forward-flow-explained?showSharer=true
submitted by /u/Beginning_Dot_1310 [link] [comments]If you do a cluster upgrade, then one node after the other gets updated.
Imagine there is pod-A on node-1.
Node-1 gets drained, and pod-A gets recreated on node-2.
Now node-2 gets updated, and again pod-A gets recreated. This time on node-3.
...
Is this a common issue? How to call that? I tried to google for that, but maybe I am missing the correct term.
How do you reduce the number of recreated pods?
submitted by /u/guettli [link] [comments]Hey hey! Who's going to Kubecrash 2024 next week? It's open-source focused, free, and virtual.
If you want the scoop on the event + cool sessions to attend, we interviewed one of the event co-founders: https://soundcloud.com/ambassador-livinontheedge/s3-ep-12-kubecrash-2024-bonus-mini-episode
submitted by /u/getambassadorlabs [link] [comments]I recently upgraded a desktop which led to turning the old desktop into a Proxmox server which ..... led to the rapid erosion of my sanity.
But as I'm this far down the rabbit hole of playing with shiny tech stuff, I figure that I may as well give Kubernetes a try.
I'm learned the basics of containerisation (most of the stuff I'm running locally is Docker containers). I'm self hosting some data visualisation stuff for work (Metabase and a database service, really like it).
I get that single node Kubernetes makes little sense. But I've heard so much about Kubernetes the past few years that I'd like to learn the concepts (and who knows ... maybe one day I'll really have a use for it).
I tried Talos OS and didn't like the lack of a GUI. I've seen Kind recommended on this sub but am not sure if it's still the best option?
Anyway ... that's what I'm looking for. If there's anything that would be a good gentle intro to all of this, please share some names.
submitted by /u/danielrosehill [link] [comments]Hello, I have two k8s clusters, which use coredns configured to forward requests to recursive servers randomly. The problem is that when we carry out maintenance on a cluster, this ends up causing problems for the other cluster that tries to forward to that server under maintenance. Is there any smarter way to configure coredns?
submitted by /u/srbolseiro [link] [comments]Hi All! I've been struggling for this for a week now, so thought it was time to ask for help.
I use AWS and the setup for our cluster is pretty standard. I have a VPC with 6 subnets (3 private, 3 public). I have an EKS cluster within the VPC that has a prometheus operator (in namespace monitoring) and a thanos receiver (in namespace monitoring-global). We have a hub and spoke method for the thanos receiver so in production, we have 3 clusters writing to one shared management cluster and this is working -> writing with external (internet-facing) load balancing.
However, there are obvious security concerns with the external load balancing execution. I am tasked with building a POC for the prometheus metrics to write to the thanos receiver through an internal (private) load balancer. The internal load balancer has been tested via bringing up test EC2 instances and ensuring they can hit the lb.
What is not working is the EKS prometheus application is not able to write to the thanos receiver without error:
caller=dedupe.go:112 component=remote level=warn remote_name=39a38c url=<internal load balancer dns>/api/v1/receive msg="Failed to send batch, retrying" err="Post \"<load balancer dns>/api/v1/receive\": context deadline exceeded"
NGINX is creating a private network load balancer and public network load balancer:
internal:
--- namespaceOverride: ingress-nginx controller: ingressClassByName: true ingressClassResource: name: nginx enabled: true default: true controllerValue: "k8s.io/ingress-nginx" service: external: enabled: false internal: enabled: true annotations: service.beta.kubernetes.io/aws-load-balancer-internal: 0.0.0.0/0 service.beta.kubernetes.io/aws-load-balancer-name: "load-balancer-internal" service.beta.kubernetes.io/aws-load-balancer-backend-protocol: tcp service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: "true" service.beta.kubernetes.io/aws-load-balancer-type: nlbexternal:
--- namespaceOverride: ingress-nginx-public fullnameOverride: ingress-nginx-public controller: ingressClassByName: true ingressClassResource: name: nginx-public enabled: true default: false controllerValue: "k8s.io/ingress-nginx-public" ingressClass: nginx-public service: annotations: service.beta.kubernetes.io/aws-load-balancer-backend-protocol: tcp service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: "true" service.beta.kubernetes.io/aws-load-balancer-type: nlb external: enabled: trueSnippet of remote-write within the Prometheus configuration:
# Source: kube-prometheus-stack/templates/prometheus/prometheus.yaml apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: name: kube-prometheus-stack-prometheus namespace: monitoring labels: app: kube-prometheus-stack-prometheus app.kubernetes.io/managed-by: Helm app.kubernetes.io/instance: kube-prometheus-stack app.kubernetes.io/version: "56.21.0" app.kubernetes.io/part-of: kube-prometheus-stack chart: kube-prometheus-stack-56.21.0 release: "kube-prometheus-stack" heritage: "Helm" spec: image: "quay.io/prometheus/prometheus:v2.50.1" version: v2.50.1 externalUrl: "<>" paused: false replicas: 1 shards: 1 logLevel: info logFormat: logfmt listenLocal: false enableAdminAPI: false retention: "10d" tsdb: outOfOrderTimeWindow: 0s walCompression: true routePrefix: "/" serviceAccountName: kube-prometheus-stack-prometheus serviceMonitorSelector: matchLabels: prometheus: monitoring serviceMonitorNamespaceSelector: {} podMonitorSelector: matchLabels: release: "kube-prometheus-stack" podMonitorNamespaceSelector: {} probeSelector: matchLabels: release: "kube-prometheus-stack" probeNamespaceSelector: {} remoteWrite: - url: <internal load balancer dns>/api/v1/receiveAny advice or instructions would be much appreciated! :D
submitted by /u/thelhr [link] [comments]I have an application where we have a bunch of certificates we use to authenticate. I want to put them in a single directory that’s not in our applications got repo but rather hosted in kubernetes and attached to our deployment in some fashion at runtime. How would I go about this?
submitted by /u/oddkidmatt [link] [comments]Hello. I need help trying to figure out why my build.yaml on my .github/workflows stalls during "
Wait for rollout to finish" step and throws "unauthorized" after some time has passed.
here is my repo:
https://github.com/olara87/hmc
Thank you.
submitted by /u/olara87 [link] [comments]I want to host many isolated databases with their own PVs and it’s on port on a load balancer however when I spin up a service type load balancer with a unique port it will assign it a new load balancer instead of using the free port on a existing load balancer which costs me an extra $10 a month. How can I have services share a load balancer or combine the services to route to many different stateful sets?
submitted by /u/oddkidmatt [link] [comments]